

1、背景
代码重构和设计模式(其实没什么关联,我硬给拉到了一起),两个似乎都是比较玄的东西。很多时候,抱着gof(写书的四人组)那本经典的《设计模式》啃个两遍下来,便觉代码之道已烂熟于心,coding中自可挥洒自如了;然而,到了实际的项目中,该怎么码还是怎么码——你问我用什么模式?咳咳,pm的需求我都忙不过来了,管他什么模式不模式的啊。至于代码重构么,功能实现出来就行了,你说代码多、乱、复杂、没条理、看不懂?喂喂,谁知道明天这代码谁维护呢,到时候看不懂管我鸟事啊? 另一方面,一些讲设计模式、讲重构的书,都是拿着java举例子,这可是含着OOP的金钥匙诞生,天生贵族血统的语言(用最好的php的同学别拍我),这些高级货似乎天生就是为这些高级语言准备的。像楼主这样工作有些年了还一直主要在码tooooooold的c/c++的老狗,码好你的功能就行了,用什么设计模式、要啥自行车?:)
偏见总是存在的。其实设计模式在技术界本不是什么新知识反而早有些过气了,不管是刚入行的新手,还是经验丰富的老鸟,都会在开发中不经意地使用出来——即使你没看过设计模式,也常会自然而然地觉得代码就该这么写。不信?可以翻翻比《设计模式》逼格更高的《POSA:Pattern Oriented Software Architecture》(前者只是软件的设计模式,后者可是架构级的设计模式:一式五本,三四千页,经典巨著,强力推荐,用翻的也要很久啊有没有~~),里面肯定有你开发过的代码的影子。而本文的重点其实是代码重构,这个主题是不会过时的,只要是有追求的程序员,一定会将重构作为日常。所以,本文的出发点,是通过总结实际开发中的一个重构小例子,说明重构对代码可维护性和可扩展性的价值、重构的节奏、以及思想是王道语言是浮云的道理;用的模式也是最基本的模式,例子也是写书时放在前言之后那5页的入门示例的水平。所以大小牛牛们就可以略过不看啦:)。笔者还想证明&正名,c++可不单单是“有类的C”!!(投最好的语言,我会给c++一票的!...冲动了,好像有点儿虚)

软件架构师装B神器,一般人我不告诉他
2、重构的一些理论
以下理论部分(粗体)摘自《重构》一书,有些枯燥,所以我也会做些直白的解读(非粗体)。
——什么是重构?重构是对软件内部结构的一种调整,目的是在不改变软件可观察行为的前提下,提高其可理解性,降低其修改成本。
说的直白一点,就是这活儿不是产品经理那边来的,不是为了新需求做的,而是有追求的程序员为了代码的可维护和可扩展性自发的升级优化行为。所以呢,不管产品经理给不给你的重构分工时,这活儿都是要干的。
为什么要重构?
改进软件设计:很多程序刚开始设计的都是牛逼哄哄一套一套的,但随着程序规模日益庞大,没人管这个那个了,代码腐烂,设计崩溃。
使软件更易理解:开发时码得飞起,码完1周后自己看不懂了,这种情况不在少数吧?
帮助找到bug:“代码码完了测试通过了,我才不会去读呢,你说自己找bug?我去,我开发完了还要自己找bug,那要测试同学干嘛?”有过这种想法的自觉举手~
提高编程速度:好的代码才更容易扩展功能,烂的代码,你想加个功能都加不进去,告诉我不是一个人有这种经历。。。
重构的时机?
三次法则、添加功能时、修补错误时、审阅代码时
三次法则的理论比较有意思:事不过三,第三次产生反感时就去重构。其实现实中,看着代码有点不爽、有点想吐,扩展功能又倍儿别扭,这时候你又不那么忙相对有时间(或者开明的产品经理大人给你的重构单独分了工时![]() ),不要犹豫,重构吧。
),不要犹豫,重构吧。
重构和性能的关系?
虽然重构可能使软件运行更慢,但它也使软件的性能优化更容易。除了对性能有严格要求的实时系统,其他任何情况下”编写快速软件“的秘密就是:首先写出可调的软件,然后调整它以求获得足够速度。
这段摘自书中的言语多少有些暧昧。其实再大胆一些说,软件的性能和优雅绝大多数情况下是对立的。然而,如果一切以极致性能为出发,也就不会有汇编之上的各种高级语言了;此外,重构损失的性能真的是软件慢的根源吗?通常不是的——性能优化也是一个专题,性能优化的利器在于找到损耗最大的热点,优化主要矛盾。而实践证明重构带来的损耗往往是很小的。
根据楼主的一些经验,影响软件维护和扩展的一个大敌是“耦合”——设计的耦合、代码的耦合、头文件的耦合、变量的耦合、函数的耦合、数据的耦合、编译的耦合、业务逻辑的耦合,这也是重构要解决的问题之一。楼主来鹅厂前是在狼厂和狼司开发广告搜索引擎和电信云平台的,其中在狼厂接触到的代码规模不那么大另外质量还可以,暂且不表;但在狼司,你能想象,一个大部门下面三四个小部门,从干了十几年的架构师到刚毕业的新兵蛋子,一堆人绞尽脑汁,从工具到人肉,用尽办法,就是为了将一个开发已超过10年、代码行数超过800万的软件进行解耦,是怎样一种场景吗?真的是轰轰烈烈甚至惨烈的一场运动。所以,在代码规模还可以控制的阶段,适时适当地对代码进行重构,是延长软件生命周期的非常有效的办法。《重构》一书中将重构的常规手法形成了方法论,但总结起来,思路也就是合并和拆分——像了就合并,多了就拆分。很多其他事情,思路无外乎都是如此吧。
3、实例
该来点干货了。首先介绍下本文优化的这个小例子,是wetest平台压力测试产品的后台ServerCenter模块源码。(你问wetest是嘛?WeTest腾讯质量开放平台(wetest.qq.com),是将鹅厂沉淀十余年、历经千款游戏锤炼的优秀测试方案和工具开放给广大游戏开发者的开放测试平台。其中的压力测试工具更是打出了如此口号——“x万8,x万8,只要x万8,机器任你压”,客官确定不要来用用看?)
ServerCenter模块是基于互娱研发部的tsf4j框架开发的,简单地说,这是压测后台的消息中转主模块,把不同的消息转发到不同的下游模块。实现层面上,该程序主逻辑就是个消息处理函数,思想非常简单,是典型的基于消息的后台逻辑。几个特点:单进程、无状态、数据共享在redis/DB等外部存储,通过增加进程个数完成scale out。这个架构方案非常简单,也是由目前的业务规模和特性决定的,后台的大拿们,这篇是讲代码重构的,架构的问题咱们在这儿就不展开聊了:)
代码V1版
遵循tsf4j的tapp写法,ServerCenterApp类是后台程序的主逻辑类,其中process_pkg是消息处理的主逻辑函数。会对不同的消息调用不同的消息processor函数。而每个消息processor函数中的流程都不简单,又拆分出了更多小函数。
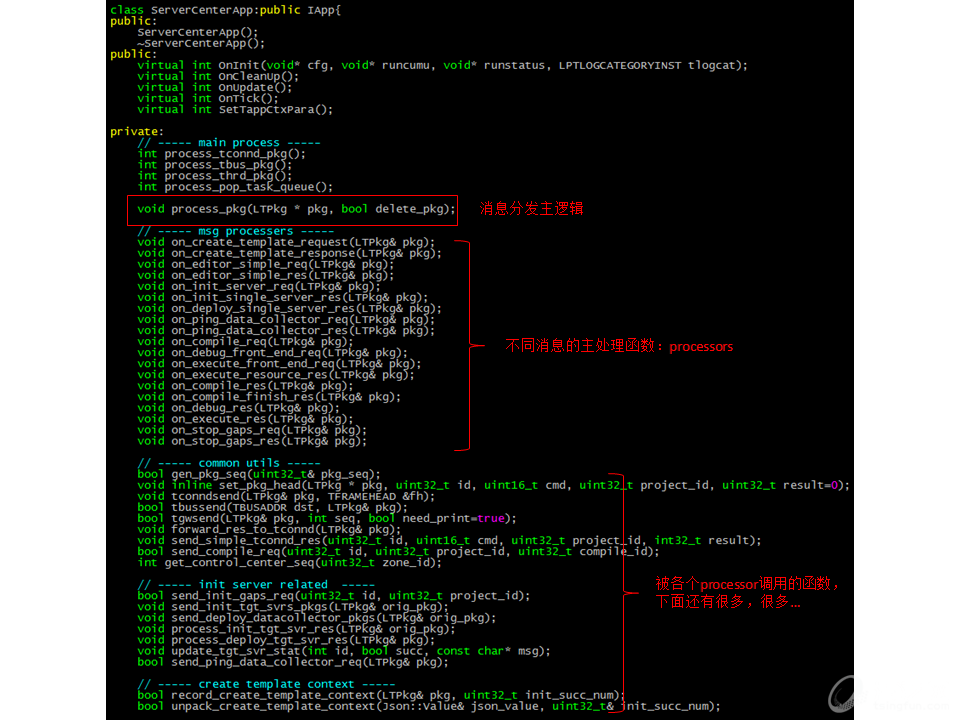
由于业务的复杂性,要处理的消息太多,所以最初的消息处理核心函数process_pkg就是这个样子的:
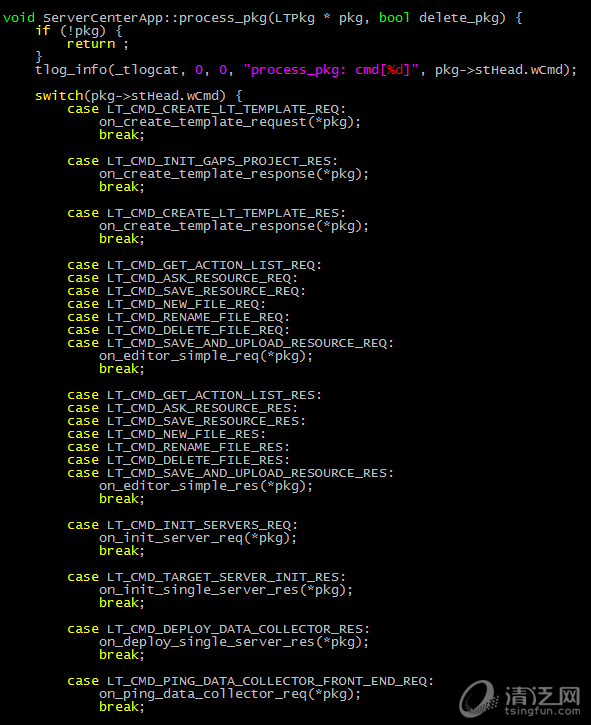
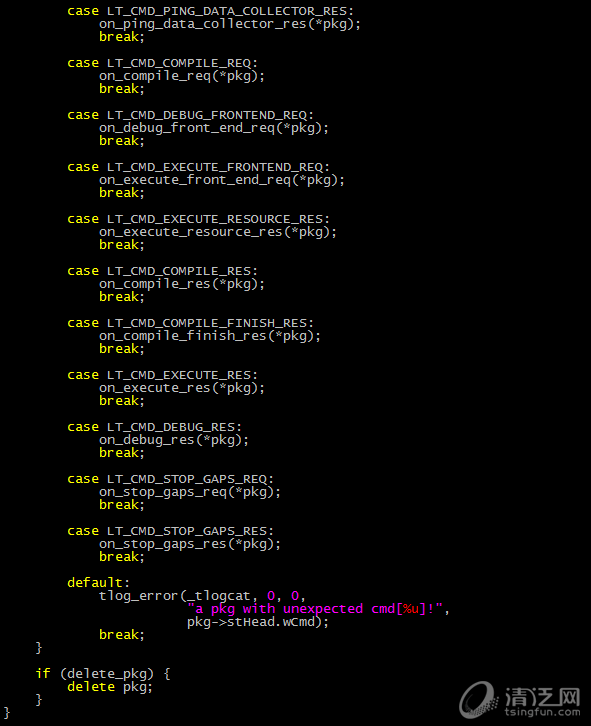
这可以说是最糙快猛的实现方式了,一个switch case函数搞定一切,不用拆分文件,不用复杂设计,很快功能就开发出来了,这代码生产率,杠杠的~
然而某天之后,每次要加新功能,都要在这个密密麻麻几千行的大文件找插入点,不爽的感觉逐渐积累起来。虽说消息处理的后台逻辑也容易写成这个样子(在狼司的时候,曾经见过一个部门,新员工进公司前1个月,啥也不干,就是读一个几千行的消息处理函数,啃完了,也就能干活了。又八远了,拉回来),但一想到可预见的时间内这代码还是我维护没跑,就浑身难受(——大力哥语录,b站的小伙伴在哪里?)。得了,那就重构下吧——这就是重构理论中提到的三次法则。
代码V2版
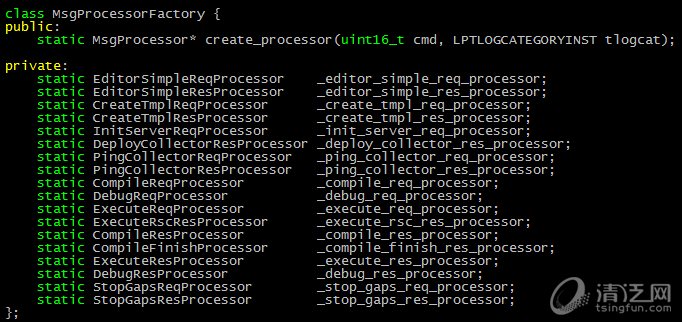
这个不同分支的消息处理代码,是很适合用设计模式里的简单工厂模式的。模如其名,简单工厂模式是非常,非常,非常简单的,原理就不再赘述了。套用到这个例子上,就是将每个消息处理逻辑抽象成一个产品(MsgProcessor),将switch case的主逻辑抽象成一个生产产品的工厂(MsgProcessorFactory)。每次主逻辑根据消息的消息码,由工厂将处理对应消息的MsgProcessor创建出来,主逻辑只调用其process_pkg即可完成消息处理,而不必关心具体的MsgProcessor是什么。
这样,程序的主逻辑和业务不同类型消息处理的耦合被解开——合并、拆分、解耦、模块化,是重构的方法也是目标。

1)重构后,ServerCenter的核心代码如下图。可见,只要通过工厂创建出来处理具体消息的MsgProcessor对象,调用其process_pkg函数即可,这样的框架代码是简易了很多而且稳定,也是OOP的一种贯彻:
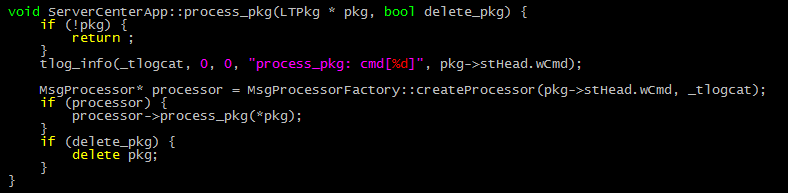
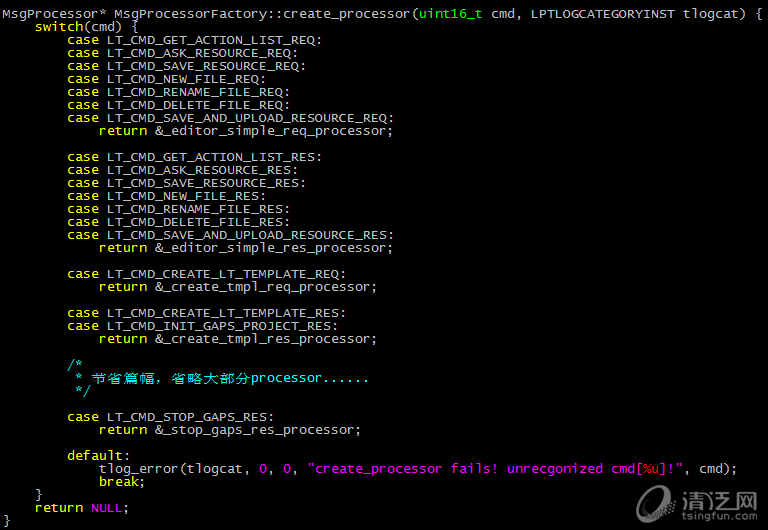
2)而重构后新增的MsgProcessorFactory工厂类,其代码如下:

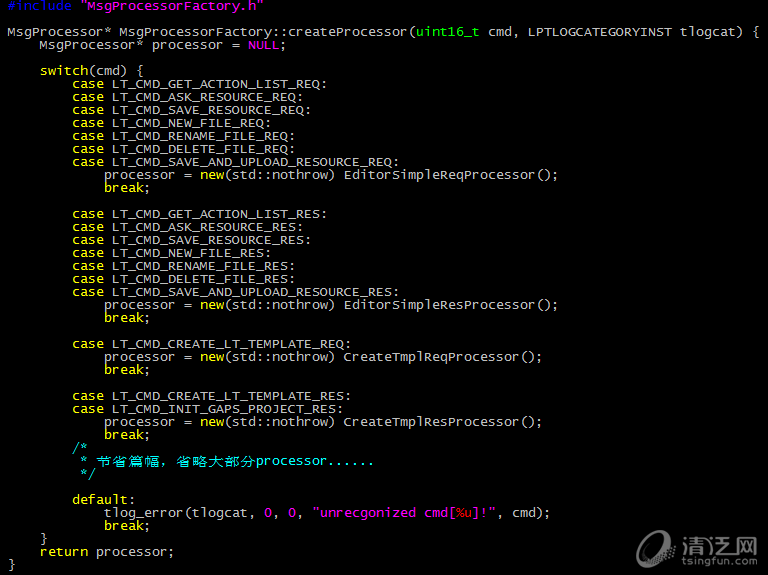
如上图,switch case的逻辑被迁移到工厂中,每次工厂中根据消息码的不同,动态new出对应的MsgProcessor类。
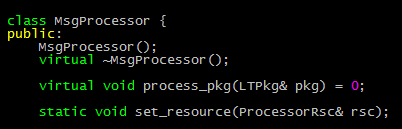
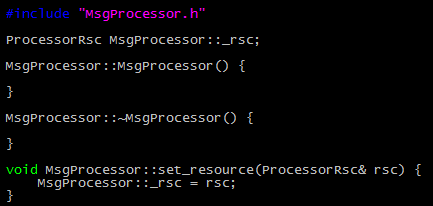
3)而真正干活的MsgProcessor的定义如下。由于在C++里没有接口一说,所以这里用纯虚函数的方式,定义出来类似接口的纯虚基类。而原来ServerCenter中的各种公共资源,如各种连接资源和收发包的缓冲,通过ProcessorRsc类传递到了Processor中,用于具体的处理:
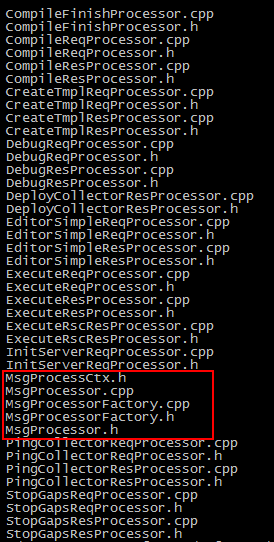
V1版代码中处理各种消息的真正干活的代码,被拆分到了MsgProcessor的各个派生类中,如下图,虽然看起来好像文件变多了,但功能点也拆分得更细,维护和更改起来相对容易了。尤其当项目规模真的变大——比如业务由不同项目组或人员维护时,这样的意义更大。
代码V3版
V2版所做的,已经足够了吗?
单就实现来看,代码已经是一种标准的设计模式了。但是带入到所采用的语言和业务场景来考虑,在每个消息处理时都在c++中new出和delete掉processor对象,可能会造成相当的内存碎片和抖动现象,尤其是在后台程序中,一般倾向于一切都有规划和预计,比如预分配好的资源和池等做法,保证系统的稳定和可控。所以在此,可以结合业务场景进行优化:MsgProcessor只是一个逻辑概念的对象,而单进程又保证类的实例是可以复用的,不需要每次动态分配。因为,可以将代码再次优化如下:
将processor定位为类级的静态变量,由主程序复用。这次的改动可以理解为对代码结构重构后的性能优化。
还有可以优化的地方吗?答案肯定是有的。每个码农都要牢记的一点是,代码的优化是在软件生命周期中一个持续的过程。回归到本例,从可维护性的角度,消息cmd和processor factory是硬编码耦合的,当前情况下没什么问题,但脑洞开一点,业务规模增加到足够大时,框架和消息可能由两拨人来维护,此时是不是用注册回调的观察者模式,可以使业务的人每次增加processor不用都找平台的人(其他项目中真实遇到的情况)?听起来好像不错,那目前为什么不这样做呢?因为不需要。虽然代码和架构的重构和优化是有收益的,但要结合项目的当前实际,在合适的阶段做合适的事情,好的架构是演进来的。当下的很多创业公司或大公司内的创业团队,往往开始时不管用什么技术/架构,走的是一条“东西做出来 -> 活下来 -> 业务量上来 -> 代码/架构/性能优化“,这样一条无奈而现实的道路。
从性能的角度,随着业务增加,要处理的消息会越来越多,这个switch作为核心路径上的热点语句,是影响性能的关键,优化的方法有switch中的热点分支前置、用索引结构如hash查找processor、甚至用编译器层面的likely分支优化等等,对于大码农们来说,很多时候,如果最终的问题归结到性能优化上,往往会比其他问题更直观和易解决:不就是找热点、抠性能嘛,招儿多了去了。总之,“先重构,再优化性能”。
4、误区
常见的误区,就是常用在开发领域的那句谚语:“你手里有一把锤子,看什么都像钉子”。
1)模式滥用
虽然本篇其实不是讲模式的,但模式应用中的一个常见问题还是要提一下,就是模式的滥用。很多人,容易为了设计模式而模式,以至代码不伦不类而更难维护。真正的高手是什么?手中无剑,心中无剑——手中无模式,心中无模式。为何无模式?早已烂熟于胸,融汇贯通,不再拘泥于形,信手拈来而恰到好处。
开发时选用的模式,要根据工程和代码规模进行合适的选择,本来简单的事情,用了不恰当的模式,反而事倍功半。比如,架构级模式中有反射模式,在很多高级语言中都是语言本身支持的(典型如java,反射是语言自身特征,也催化出了spring这种优秀框架)。而在不支持反射的语言中,这种模式的思想就需要用本语言重新实现。比如c语言,本身无反射,那在一些大型电信设备的软件平台中,自己实现一套完整的反射框架,会将模块配置加载的动态性提升到了一个很高的层级,是很有收获的。可是同学你说你写个简单的hello world也要实
现个反射模式那就是脑抽了。
2)重构!=重做
重构的定义里有很重要的一点,就是“软件内部结构的一种调整”。调整是什么意思呢?就是调一调,整一整,而不是随随便便就推倒了重来。常见的重做有两种场景:一种是,软件烂的不能再烂了、扛不住了、没法维护了、没法正常工作了,重构的成本远不如重做一个了,那就重来吧(这是正确的姿势);另一种,某个蛋疼的家伙为了一些原因(挖新坑,找新活等等),动不动就和大家吹风,”嘿,这玩意儿我们重做一个吧“,好的,这哥们就是团队的不稳定因素(这是错误的姿势),当然如果团队闲到正常开发任务外有大把时间无所事事那就无可厚非另当别论了。
总而言之,对一个已上线运行并具有一定业务量的模块或系统,从头再来有非常大的风险,一定要经过全面的分析和评估,慎之又慎。高手总是像神医一样对现有的系统进行改善和优化,而不是把人砍了再造一个。当然,难度也很大,否则,“重构”,就这两个字的事,怎么能单独出书和形成一套方法论呢:)
 有C++难题,加我!
有C++难题,加我!