

1. Safe Reclamation Methods
Folly 的 Hazard Pointer 实现中有一段注释,详细描述了 C++ 里几种主流的安全内存回收方法,列表如下:
| 优点 | 缺点 | 场景 | |
|---|---|---|---|
| Locking | 易用 | 读高开销 / 抢占式 / 死锁 | 非性能敏感 |
| Reference Couting | 自动回收 / 线程无关 / 免于死锁 | 读高开销 / 抢占式 | 需要自动回收 |
| Read-copy-update (RCU) | 简单 / 高速 / 可拓展 | 对阻塞敏感 | 性能敏感 |
| Hazard Pointer | 高速 / 可拓展 / 阻塞场景可用 | 性能依赖 TLS | 性能敏感 / 读多写少 |
C++ 标准库中提供了锁和引用计数方案。锁的缺点很明显,无论是哪种锁,在读的时候都会产生较大的开销。引用计数则相对好一些,但每次读取都需要修改引用计数,高并发场景下这样的原子操作也会成为性能瓶颈,毕竟原子加对应的 CPU 指令 lock add 也可以看成是微型锁。
Linux 内核中提供了 RCU 方法,笔者目前对此还没有太多的了解。本文主要介绍 Hazard Pointer,一种无锁编程中广泛使用的安全内存回收方法,适用于需要高性能读、读多写少的场景。其论文可参考文献 1,标准草案可参考文献 2,代码实现可参考 Folly 中的 HazPtr。
2. Hazard Pointer
首先回忆下引用计数的做法:
仔细观察可以发现:
- 每一次的读取操作对应引用计数中增加的数值 1;
- 当所有的读取操作都完成时引用计数归 0,此时内存可以安全回收。
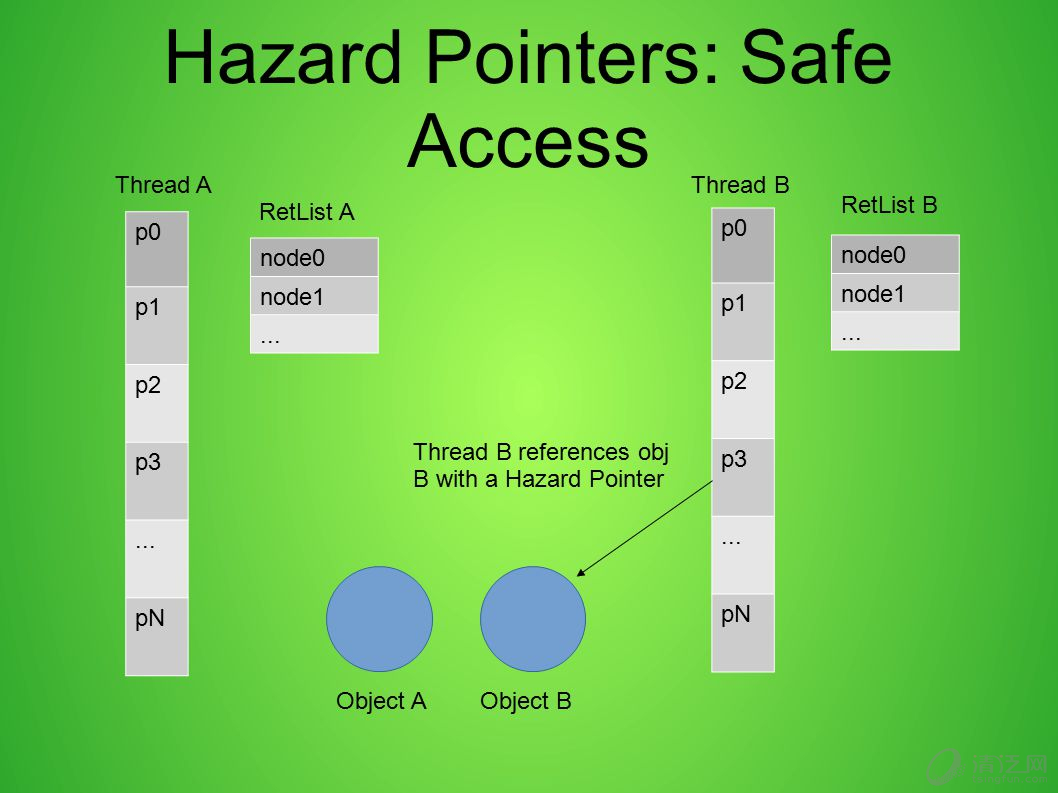
总结起来,当对象正在使用时,就不能回收内存。每一个“正在使用”都需要对应一个标记,引用计数使用的标记是计数数值一,对应的原子操作性能问题就成为它无法摆脱的原罪。而 Hazard Pointer 使用的标记更为轻巧,一般通过在链表中标记该对象的指针实现,回收时如果发现链表中有对应的指针就不进行内存回收,将标记的复杂度转移到回收部分,也就更适合读多写少的场景。Hazard Pointer 的简单实现(在线执行):
简单解释下原理。Hazard Pointer 申请读取时,会在对象链表中申请一个空位置,将对象的指针写入该位置中,读取结束时将该位置重新置空即可;而发生更新时,将更新替换下来的旧指针加入退休列表里,退休列表积攒到一定程度时则检查哪些对象已经不在对象链表中,不再使用的则可以执行删除。
如果使用 std::shared_ptr 实现上述逻辑,你会发现它的执行速度还要高于上述代码。原因在于这里实现的 Hazard Pointer 没有使用非对称内存屏障和线程本地存储优化。如果仔细观察,可以发现 Acquire 函数中使用顺序一致性内部屏障 pointer->target_ = ...,x86 平台上会翻译为 mfence 指令,与 lock add 指令相比也不遑多让。在读多写少的前提下,可以将读写两边的屏障替换为非对称内存屏障,将读部分的开销转移到写部分中。可参考先前内存屏障博文中的介绍。
另一方面,Hazard Pointer 的高性能依赖于平台上线程本地存储(TLS)的性能。单纯使用 CAS 更新全局的对象链表和退休列表的性能太低,可以使用 TLS 做为缓冲层,这样大部分时间都是更新本线程的数据。这部分可以参考 Folly 中的 ThreadLocalPtr,其中实现了遍历所有线程 TLS 的黑魔法。
References
- "Hazard Pointers: Safe Memory Reclamation forLock-Free Objects", Maged M. Michael
- "Proposed Wording for Concurrent Data Structures: Hazard Pointer and ReadCopyUpdate (RCU)", Open Standards
| 以下内容来自维基百科: |
-----------------------------
在多线程环境中, 冒险指针是一种解决由无锁 数据结构中的节点动态内存管理引起的问题的方法。 这些问题通常仅在没有自动垃圾收集的环境中出现。
使用比较和交换原语的任何无锁数据结构都必须处理ABA问题。 例如,在使用链表实现的无锁堆栈中,一个线程可能正在尝试从堆栈的前面弹出项目(A→B→C)。 它会记住自栈顶而下的第二个值“B”,然后执行 compare_and_swap(target=&head, newvalue=B, expected=A) 不幸的是,在此操作正在执行时,另一个线程可能执行了两次弹出操作,然后将A推回顶部,从而导致堆栈(A→C)。 比较并交换成功将“ head”与“ B”交换,结果是堆栈现在包含垃圾数据(指向已经被释放的元素“ B”的指针)。
此外,任何包含以下形式代码的无锁算法
在没有自动垃圾收集的情况下,它还面临另一个主要问题。 在这两行之间,另一个线程可能会弹出this->head指向的节点并对其进行内存分配,这意味着通过第二行上的currentNode进行的内存访问读取了已释放的内存(实际上可能已经被另外一部分程序用在了不同的地方)。
冒险指针可用于同时解决这两个问题。 在使用冒险指针的系统中,每个线程都保留一个冒险指针的列表 ,这些指针指示该线程当前正在访问的节点。 (在许多系统中,此“列表”可能只限于一个或两个元素。 )冒险指针列表上的节点不得被任何其他线程修改或释放。
Each reader thread owns a single-writer/multi-reader shared pointer called "hazard pointer." When a reader thread assigns the address of a map to its hazard pointer, it is basically announcing to other threads (writers), "I am reading this map. You can replace it if you want, but don't change its contents and certainly keep your deleteing hands off it."
——Andrei Alexandrescu and Maged Michael,Lock-Free Data Structures with Hazard Pointers
当线程希望删除一个节点时,它将其放置在“稍后释放”的节点列表上,但实际上直到其他线程的危险列表中没有包含指针时才真正释放该节点的内存。 可以通过专用的垃圾回收线程来完成此手动垃圾回收(如果所有线程共享“稍后释放”的列表);或者,可以由每个工作线程自行清除“待释放”列表,作为诸如“ pop”之类的操作的一部分(在这种情况下,每个工作线程可以负责其自己的“待释放”列表)。
在2002年,IBM的Maged Michael提出了关于冒险指针技术的美国专利申请, 但该申请在2010年被放弃。
冒险指针的替代方法包括引用计数 。
 有C++难题,加我!
有C++难题,加我!