

痛并快乐着

今天讲讲C/C++程序的常用调试手段,介绍调试手段之前,我会首先对开发过程中可能遇到的问题进行一个总结,大概可以把问题分为以下几类:
必现的程序逻辑错误
概率性错误
进程卡死或挂掉,系统变卡,cpu调度变慢
程序正常,程序性能瓶颈分析
三年下来,排查的问题不少,该遇到的都遇到了,不该遇到的也遇到了,只能说五味杂陈。
现在的我大概是这样的,一段程序放在我面前,我会从以下几个角度去考虑它。
-
功能
这段程序是用来实现什么功能? 是否可以满足功能的需求?是否可以对职责场景覆盖全面? -
代码规范
变量名、函数名、类名是否简单、精准的表达变量的含义?所有变量命名是否可以保持一致性?缩进,换行,可读性如何?
(驼峰、下划线,这个根据公司或者谷歌等的编码规范去做,至于缩进、换行、注释等,可以在经常使用的ide上安装相关格式化插件) -
是否涉及动态资源
是否有申请动态内存,文件描述符等,执行完是否有正确释放?指针等操作是否规范? -
性能如何
是否有一些执行耗时的操作,I/O,网络文件下载,文件解析等,是否可以进行优化?是否会影响到功能体验?使用异步线程执行会更好吗? -
多线程相关
是否涉及到多线程,临界区访问是否正常?会引入多线程问题吗?接口可重入吗?会造成死锁吗? -
是否符合常见的设计原则
类继承是否符合里氏替换原则?接口做的事情是不是太多了,是否符合单一职责原则?程序是否有其他地方也用到,可以复用吗?是否有重复代码,可以精简吗?
大概就这些吧,如果都考虑到了,这个程序就完美了吗? 不不不,程序只是在当前场景下表现正常,也许在某个时刻某个不知名的场景下,还是会出问题,问题原因可能是因为其他模块代码的影响,可能是系统环境变了,可能是某些不知名的原因。。。。
只能说程序出问题的可能性太高了,因此程序调试和排错的手段,就显得异常重要!
必现的程序逻辑错误
对于必现的程序逻辑错误,一开始,我们往往会选择在关键地方加上一些 log 来进行问题排查(有些比较特殊场景只能加 log ),在我看来,采用这种方式可以,前提是你对代码的业务流程已经比较熟悉,然后你为了确认一下自己的判断,去加 log(可以在ide 中设置一些快捷键),因为你知道 log 加在哪里最关键,而不是漫无目的,否则效率会奇低。
另一种方式当然是使用调试工具,单步调试,随时查看栈中任意数据,Linux 下使用GDB,windows 直接用宇宙第一ide:Visual Studio,至于 android 调试 Native C++ 程序,现在公司是修改完代码、编译,然后用 adb pull 到 android 系统上(公司开发的是android系统软件,不是app), 说实话,实在无语,原因是 android 系统的 ANR 机制,长时间不操作,调试进程会被系统杀掉,这个后面有时间再研究一下,肯定有更好的办法(不能把ANR机制关了吗 ?)。
概率性错误
此类错误,那就涉及到场景复现的问题,如果有拿到有效的 log,那还好,可以根据log进行分析,找出问题的根本原因;最怕的就是测试或者客户测反馈一个bug,但是没有效 log和相关配置,然后本地又复现不出来,这种比较麻烦,能做的无非就是复现,或者做一些促进复现的工作,比如写一些测试脚本,然后在代码流程中加入一些有助于问题分析的 log,然后放到反馈的环境下去挂机。
如果最后挂机也没有复现,客户侧也没有再复现,那怎么办,最近就遇到一个,实在太坑了,工厂反馈的bug,100台中大概出现4台,系统升级过程中部分配置没有生效,导致升级上来,系统直接异常,而且完全没有有效的 log。
对于此类概率性问题,之前其实已经有处理过一些,大部分原因都是两个进程/线程的启动时序出现变动,并且两者间又存在依赖导致的, 此类问题相对来说比较难查,因为你要对两个大的模块都要有一个整体的了解,两模块间的关系要分析的很清楚。这种涉及多个模块的问题,比较考验你的代码阅读能力,以及对整体框架的理解。
说回那个比较坑的系统升级配置丢失问题,我详细的查看了一下系统的启动脚本(shell) 以及 该升级模块的代码,然后抛出了几个可能的原因,预约了一个会议室,把部门主管和其他部门的相关模块都拉上,一起讨论分析,因为工厂反馈的,比较着急,要出货(哈哈),大家一起确认完,大概也就这几个原因,比较可能的是,触发升级的进程没有去设置环境变量,升级转换配置的模块在运行的过程中异常挂掉了,升级模块进程有依赖另一个进程,而且两者间需要保证确定的启动优先顺序等,但是不能确定啊,所以我改了下脚本,在两种最可能出现的场景下,让系统循环运行,这种人力做基本不可能,挂了一个周末,问题还是没有复现。
无解了是吗? 确实是,因为你不知道原因啊,那怎么对症下药呢? 是的,我们虽然不知道确切的原因,但是我们知道原因就是其中的一个,所以当时做了个容错,保证就算出现由其中任何一个原因导致的该问题,我们都可以用这个容错修改规避掉,其实很简单,在 shell 脚本中加入一个判断就可以了,升级模块代码,需要成功以后,才去设置成功的环境变量,否则下次重启还是需要重新执行配置转换流程,然后还补充了一些关键的log,由于问题概率非常低,容错可以保证客户侧的正常使用,然后如果问题真的出现,也可以及时反馈分析。
进程挂掉,系统变卡
系统变卡,就是CPU 调度变慢,那这肯定是哪个程序一直占用CPU,导致其他程序无法被执行。 常见的原因可能是,内存变少,导致系统分配内存的时候,需要频繁的进行内存置换操作,进而导致系统变慢,内存相关可以看下之前的另一篇博客Linux 系统内存分析,如果置换到后面,物理内存和交换空间都用完了,系统将触发oom-killer,把来申请内存的进程直接杀掉了,这也是导致进程挂掉的可能原因之一; 或者某个程序死循环了,而且还没有超过系统设置的默认函数栈大小(ulimit –s, 超过就栈溢出,直接收到系统信号,然后进程直接被杀了),导致系统卡住;最后就是指针误操作(访问非法内存,数组越界也属于此类),这种算是最基本的错误了,需要无时无刻警惕,有一定经验后,这种错误基本就不会犯了。
对于该类所谓的疑难问题,最困恼我们的无非就是定位,定位到模块,定位到进程/线程,定位到具体代码行。公司当前有几个系统平台采用的方法是对异常信号(signal)注册回调,然后进行堆栈回溯,最后将堆栈保存到本地文件、标准输出、远程服务器等,这样比较方便,实时性也较好(对于一些比较低端的系统,承受不来valgrind等高级工具的,还是不错的选择),可以看下这篇文章,基本是一样的Android Native Crash。
程序正常,程序性能瓶颈分析
工欲善其事,必先利其器! 在 Linux 系统下,有很多很棒的、来源的性能分析工具,我现在有这样一个想法,如果你开发多平台使用的程序,那么请你把 Linux 作为你编译、调试、性能调优的大本营。你想想编译服务器(Linux)上支持的 20 个线程,同时编译你的程序,那速度简直快到飞起,像我们使用 NDK 到自己的 windows 系统下编译,整份代码编完需要 10 分钟以上,Linux 下直接ndk-build -j20,2~3 分钟就搞定,而且编译服务器所有人共享。
性能调优,你写出来的代码,你如何知道它有没有坑呢? 怎么知道它是完美的呢? 我们需要一款计分工具,Linux下常用的有 gprof、google-perftools、valgrind等。我们看一下valgrind,看下它搭配kcachegrind 导出的分析图,可以说是相当细致,里面有各个函数执行的时间占比,调用次数。
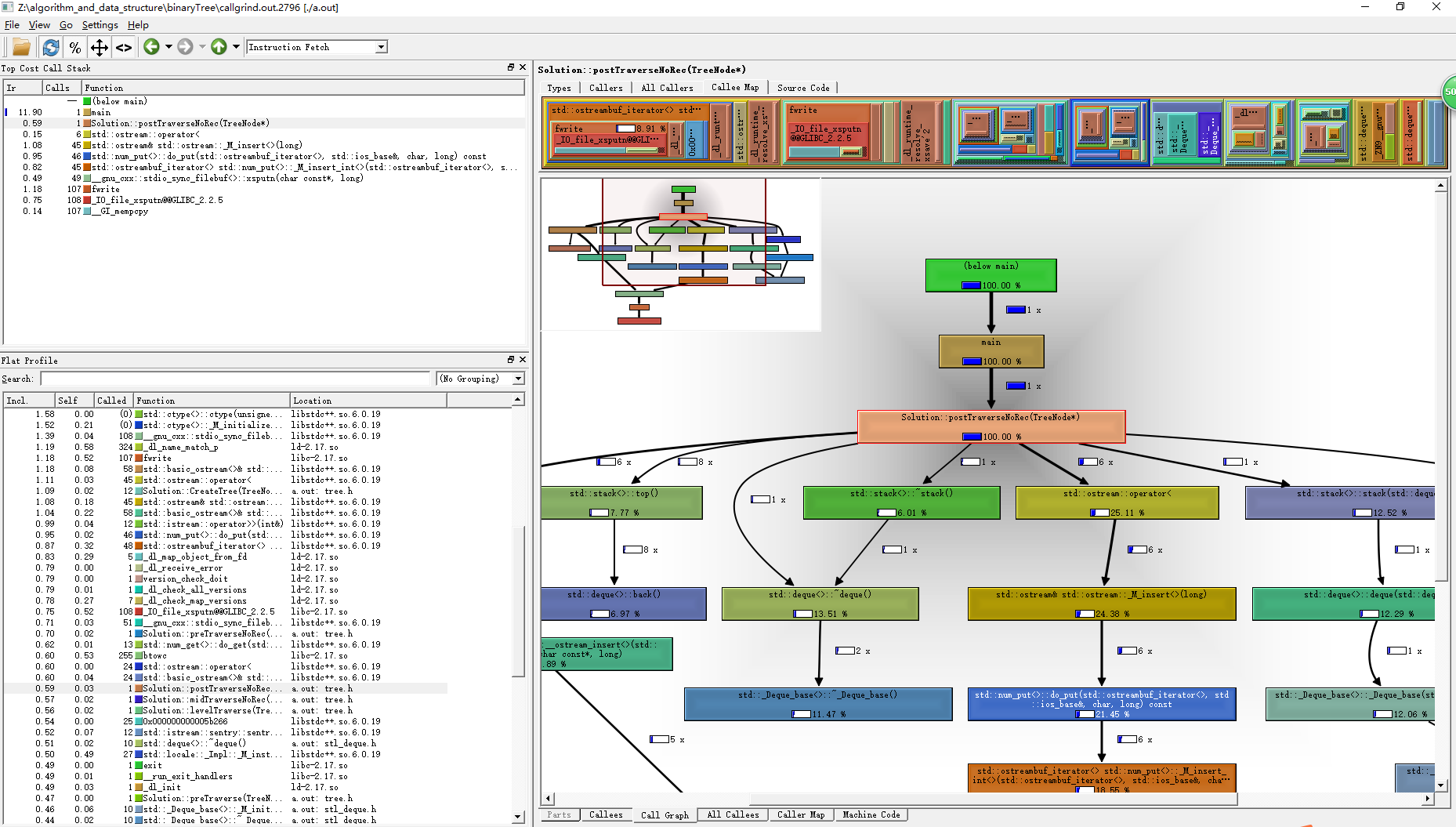
下面这个是valgrind + gprof2dot.py + dot 导出图的一部分,太大了,截了关键的一部分,程序是练手的二叉树算法:

kcachegrind:https://sourceforge.net/projects/precompiledbin/
原文标题《Linux-程序异常排查》,作者:Jiayun-Ye
来源:https://mikeblog.top/2019/03/05/Linux-程序异常排查
 有C++难题,加我!
有C++难题,加我!