

采用servlet3.0,异步化servlet,提高整个系统的吞吐量
http请求经过Nginx,通过负载均衡算法分到到App的某一节点,这一层层扩容起来比较简单。
除了利用cookie保存少量用户部分信息外(cookie一般不能超过4K的大小),对于App接入层,保存有用户相关的session数据,但是有些反向代理或者负载均衡不支持对session sticky支持不是很好或者对接入的可用性要求比较高(app接入节点宕机,session随之丢失),这就需要考虑session的集中式存储,使得App接入层无状态化,同时系统用户变多的时候,就可以通过增加更多的应用节点来达到水平扩展的目的。
Session的集中式存储,需要满足以下几点要求:
a、高效的通讯协议
b、session的分布式缓存,支持节点的伸缩,数据的冗余备份以及数据的迁移
c、session过期的管理
4. 业务服务
代表某一领域的业务提供的服务,对于电商而言,领域有用户、商品、订单、红包、支付业务等等,不同的领域提供不同的服务,
这些不同的领域构成一个个模块,良好的模块划分和接口设计非常重要,一般是参考高内聚、接口收敛的原则,
这样可以提高整个系统的可用性。当然可以根据应用规模的大小,模块可以部署在一起,对于大规模的应用,一般是独立部署的。
高并发:
业务层对外协议以NIO的RPC方式暴露,可以采用比较成熟的NIO通讯框架,如netty、mina
可用性:
为了提高模块服务的可用性,一个模块部署在多个节点做冗余,并自动进行负载转发和失效转移;
最初可以利用VIP+heartbeat方式,目前系统有一个单独的组件HA,利用zookeeper实现(比原来方案的优点)
一致性、事务:
对于分布式系统的一致性,尽量满足可用性,一致性可以通过校对来达到最终一致的状态。
5. 基础服务中间件
1) 通信组件
通信组件用于业务系统内部服务之间的调用,在大并发的电商平台中,需要满足高并发高吞吐量的要求。
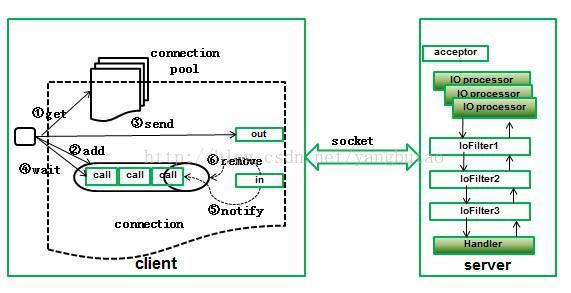
整个通信组件包括客户端和服务端两部分。
客户端和服务器端维护的是长连接,可以减少每次请求建立连接的开销,在客户端对于每个服务器定义一个连接池,初始化连接后,可以并发连接服务端进行rpc操作,连接池中的长连接需要心跳维护,设置请求超时时间。
对于长连接的维护过程可以分两个阶段,一个是发送请求过程,另外一个是接收响应过程。在发送请求过程中,若发生IOException,则把该连接标记失效。接收响应时,服务端返回SocketTimeoutException,如果设置了超时时间,那么就直接返回异常,清除当前连接中那些超时的请求。否则继续发送心跳包(因为可能是丢包,超过pingInterval间隔时间就发送ping操作),若ping不通(发送IOException),则说明当前连接是有问题的,那么就把当前连接标记成已经失效;若ping通,则说明当前连接是可靠的,继续进行读操作。失效的连接会从连接池中清除掉。
每个连接对于接收响应来说都以单独的线程运行,客户端可以通过同步(wait,notify)方式或者异步进行rpc调用,
序列化采用更高效的hession序列化方式。
服务端采用事件驱动的NIO的MINA框架,支撑高并发高吞吐量的请求。
2) 路由Router
在大多数的数据库切分解决方案中,为了提高数据库的吞吐量,首先是对不同的表进行垂直切分到不同的数据库中,
然后当数据库中一个表超过一定大小时,需要对该表进行水平切分,这里也是一样,这里以用户表为例;
对于访问数据库客户端来讲,需要根据用户的ID,定位到需要访问的数据;
数据切分算法,
根据用户的ID做hash操作,一致性Hash,这种方式存在失效数据的迁移问题,迁移时间内服务不可用
维护路由表,路由表中存储用户和sharding的映射关系,sharding分为leader和replica,分别负责写和读
这样每个biz客户端都需要保持所有sharding的连接池,这样有个缺点是会产生全连接的问题;
一种解决方法是sharding的切分提到业务服务层进行,每个业务节点只维护一个shard的连接即可。
见图(router)
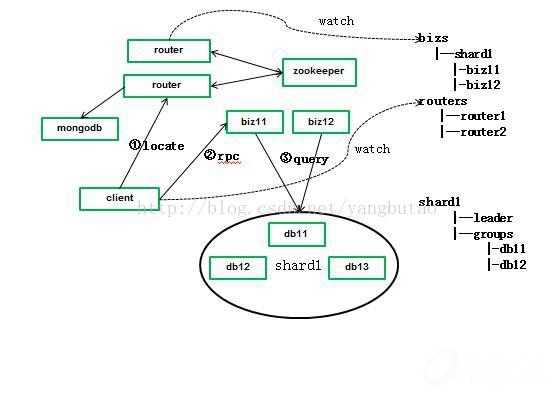
路由组件的实现是这样的(可用性、高性能、高并发)
基于性能方面的考虑,采用mongodb中维护用户id和shard的关系,为了保证可用性,搭建replicatset集群。
biz的sharding和数据库的sharding是一一对应的,只访问一个数据库sharding.
biz业务注册节点到zookeeper上/bizs/shard/下。
router监听zookeeper上/bizs/下节点状态,缓存在线biz在router中。
client请求router获取biz时,router首先从mongodb中获取用户对应的shard,router根据缓存的内容通过RR算法获取biz节点。
为了解决router的可用性和并发吞吐量问题,对router进行冗余,同时client监听zookeeper的/routers节点并缓存在线router节点列表。
3) HA
传统实现HA的做法一般是采用虚拟IP漂移,结合Heartbeat、keepalived等实现HA,
Keepalived使用vrrp方式进行数据包的转发,提供4层的负载均衡,通过检测vrrp数据包来切换,做冗余热备更加适合与LVS搭配。Linux Heartbeat是基于网络或者主机的服务的高可用,HAProxy或者Nginx可以基于7层进行数据包的转发,因此Heatbeat更加适合做HAProxy、Nginx,包括业务的高可用。
在分布式的集群中,可以用zookeeper做分布式的协调,实现集群的列表维护和失效通知,客户端可以选择hash算法或者roudrobin实现负载均衡;对于master-master模式、master-slave模式,可以通过zookeeper分布式锁的机制来支持。
4) 消息Message
对于平台各个系统之间的异步交互,是通过MQ组件进行的。
在设计消息服务组件时,需要考虑消息一致性、持久化、可用性、以及完善的监控体系。
业界开源的消息中间件主要RabbitMQ、kafka有两种,
RabbitMQ,遵循AMQP协议,由内在高并发的erlanng语言开发;kafka是Linkedin于2010年12月份开源的消息发布订阅系统,它主要用于处理活跃的流式数据,大数据量的数据处理上。
对消息一致性要求比较高的场合需要有应答确认机制,包括生产消息和消费消息的过程;不过因网络等原理导致的应答缺失,可能会导致消息的重复,这个可以在业务层次根据幂等性进行判断过滤;RabbitMQ采用的是这种方式。还有一种机制是消费端从broker拉取消息时带上LSN号,从broker中某个LSN点批量拉取消息,这样无须应答机制,kafka分布式消息中间件就是这种方式。
消息的在broker中的存储,根据消息的可靠性的要求以及性能方面的综合衡量,可以在内存中,可以持久化到存储上。
对于可用性和高吞吐量的要求,集群和主备模式都可以在实际的场景应用的到。RabbitMQ解决方案中有普通的集群和可用性更高的mirror queue方式。 kafka采用zookeeper对集群中的broker、consumer进行管理,可以注册topic到zookeeper上;通过zookeeper的协调机制,producer保存对应topic的broker信息,可以随机或者轮询发送到broker上;并且producer可以基于语义指定分片,消息发送到broker的某分片上。
总体来讲,RabbitMQ用在实时的对可靠性要求比较高的消息传递上。kafka主要用于处理活跃的流式数据,大数据量的数据处理上。
5) Cache&Buffer
Cache系统
在一些高并发高性能的场景中,使用cache可以减少对后端系统的负载,承担可大部分读的压力,可以大大提高系统的吞吐量,比如通常在数据库存储之前增加cache缓存。
但是引入cache架构不可避免的带来一些问题,cache命中率的问题, cache失效引起的抖动,cache和存储的一致性。
Cache中的数据相对于存储来讲,毕竟是有限的,比较理想的情况是存储系统的热点数据,这里可以用一些常见的算法LRU等等淘汰老的数据;随着系统规模的增加,单个节点cache不能满足要求,就需要搭建分布式Cache;为了解决单个节点失效引起的抖动 ,分布式cache一般采用一致性hash的解决方案,大大减少因单个节点失效引起的抖动范围;而对于可用性要求比较高的场景,每个节点都是需要有备份的。数据在cache和存储上都存有同一份备份,必然有一致性的问题,一致性比较强的,在更新数据库的同时,更新数据库cache。对于一致性要求不高的,可以去设置缓存失效时间的策略。
Memcached作为高速的分布式缓存服务器,协议比较简单,基于libevent的事件处理机制。
Cache系统在平台中用在router系统的客户端中,热点的数据会缓存在客户端,当数据访问失效时,才去访问router系统。
当然目前更多的利用内存型的数据库做cache,比如redis、mongodb;redis比memcache有丰富的数据操作的API;redis和mongodb都对数据进行了持久化,而memcache没有这个功能,因此memcache更加适合在关系型数据库之上的数据的缓存。
Buffer系统
用在高速的写操作的场景中,平台中有些数据需要写入数据库,并且数据是分库分表的,但对数据的可靠性不是那么高,为了减少对数据库的写压力,可以采取批量写操作的方式。
开辟一个内存区域,当数据到达区域的一定阀值时如80%时,在内存中做分库梳理工作(内存速度还是比较快的),后分库批量flush。
6) 搜索
在电子商务平台中搜索是
 有C++难题,加我!
有C++难题,加我!