

的region无法访问,等待failover生效。
通过Master维护各Region Server健康状况和Region分布。
多个Master,Master宕机有zookeeper的paxos投票机制选取下一任Master。Master就算全宕机,也不影响Region读写。Master仅充当一个自动运维角色。
HDFS为分布式存储引擎,一备三,高可靠,0数据丢失。
HDFS的namenode是一个SPOF。
为避免单个region访问过于频繁,单机压力过大,提供了split机制
HBase的写入是LSM-TREE的架构方式,随着数据的append,HFile越来越多,HBase提供了HFile文件进行compact,对过期数据进行清除,提高查询的性能。
Schema free
HBase没有像关系型数据库那样的严格的schema,可以自由的增加和删除schema中的字段。
HBase分布式数据库,对于二级索引支持的不太好,目前只支持在rowkey上的索引,所以rowkey的设计对于查询的性能来讲非常关键。
7. 管理与部署配置
统一的配置库
部署平台
8. 监控、统计
大型分布式系统涉及各种设备,比如网络交换机,普通PC机,各种型号的网卡,硬盘,内存等等,还有应用业务层次的监控,数量非常多的时候,出现错误的概率也会变大,并且有些监控的时效性要求比较高,有些达到秒级别;在大量的数据流中需要过滤异常的数据,有时候也对数据会进行上下文相关的复杂计算,进而决定是否需要告警。因此监控平台的性能、吞吐量、已经可用性就比较重要,需要规划统一的一体化的监控平台对系统进行各个层次的监控。
平台的数据分类
应用业务级别:应用事件、业务日志、审计日志、请求日志、异常、请求业务metrics、性能度量
系统级别:CPU、内存、网络、IO
时效性要求
阀值,告警:
实时计算:
近实时分钟计算
按小时、天的离线分析
实时查询
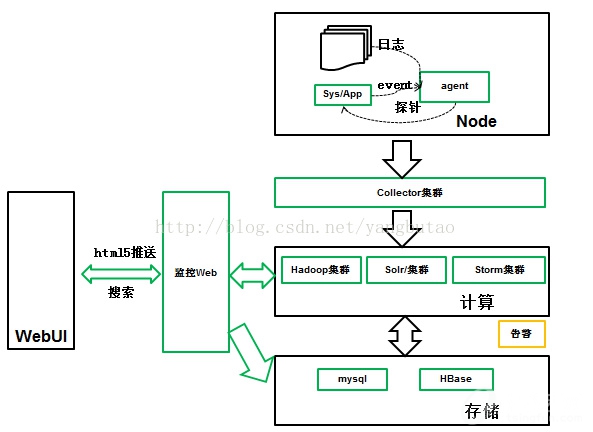
架构
节点中Agent代理可以接收日志、应用的事件以及通过探针的方式采集数据,agent采集数据的一个原则是和业务应用的流程是异步隔离的,不影响交易流程。
数据统一通过collector集群进行收集,按照数据的不同类型分发到不同的计算集群进行处理;有些数据时效性不是那么高,比如按小时进行统计,放入hadoop集群;有些数据是请求流转的跟踪数据,需要可以查询的,那么就可以放入solr集群进行索引;有些数据需要进行实时计算的进而告警的,需要放到storm集群中进行处理。
数据经过计算集群处理后,结果存储到Mysql或者HBase中。
监控的web应用可以把监控的实时结果推送到浏览器中,也可以提供API供结果的展现和搜索。
 有C++难题,加我!
有C++难题,加我!