

在没有共享存储的情况下解决非结构化数据高可靠性存储的问题
1、问题产生背景
三台TOMCAT 服务器通过负载均衡设备对外提供WEB服务。怎么保证三台服务器中的数据一样呢?
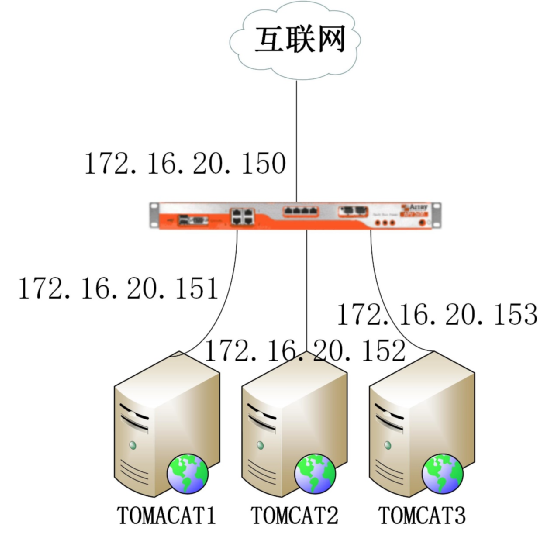
1.1最开始的解决方案:
在其中一台服务器上开启NFS服务,其他两台服务器挂着NFS目录。所有非结构化和可变数据放在NFS目录里面。这样一来解决了三台服务器内容一致的问题。
但是新的问题又来了,万一提供NFS服务器挂了怎么办,系统存在单点故障。
如果在三台服务器中创建相同的目录。然后使用Rsync做实施同步怎样呢?
这种方式有两个最重要的缺陷。由于Rsync是对文件进行操作,层次比价高,使用Rsync对文件夹进行同步,会占用大量的磁盘I/O和网络带宽。同时如果正在拷贝的文件在大量频繁的更改,Rsync将会变得无所适从而产生冲突。
另一种情况假如 tomact2,tomcat3同步tomcat1的目录,当tomcat1挂了之后,负载均衡会把访问分配到tomcat2和3,这个时候tomcat2和3彼此独立。客户分别对这两台机器进行读写于是数据又不同步了。
1.2 分布式文件系统
对网上很多分布式文件系统进行了简单的了解和阅读。
如Lustre、
HDFS
MogileFS
FastDFS
OpenAFS
MooseFS
pNFS
GoogleFS
TFS(taobao)。
仔细阅读下来,发现上述系统不是不成熟,就是太大了,以至于根本就没有合适的环境去部署。寻寻觅觅中一个叫drbd的软件进入了视线
下面是一些简介
Distributed Replicated Block Device(DRBD)是一种基于软件的,无共享,复制的存储解决方案,在服务器之间的对块设备(硬盘,分区,逻辑卷等)进行镜像。DRBD工作在内核 当中的,类似于一种驱动模块。DRBD工作的位置在文件系统的buffer cache和磁盘调度器之间,通过tcp/ip发给另外一台主机到对方的tcp/ip最终发送给对方的drbd,再由对方的drbd存储在本地对应磁盘 上,类似于一个网络RAID-1功能。在高可用(HA)中使用DRBD功能,可以代替使用一个共享盘阵。本地(主节点)与远程主机(备节点)的数据可以保 证实时同步。当本地系统出现故障时,远程主机上还会保留有一份相同的数据,可以继续使用。DRBD的架构如下图
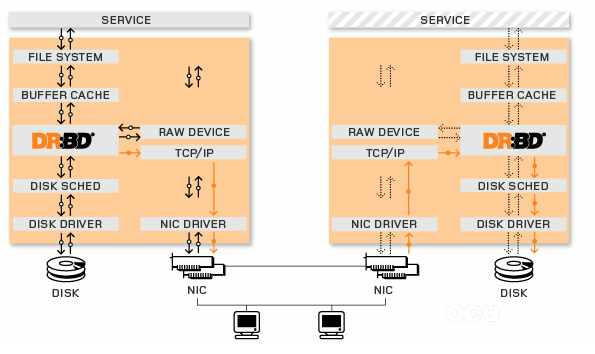
底层设备支持
DRBD需要构建在底层设备之上,然后构建出一个块设备出来。对于用户来说,一个DRBD设备,就像是一块物理的磁盘,可以在上面内创建文件系统。DRBD所支持的底层设备有以下这些类:
1、一个磁盘,或者是磁盘的某一个分区;
2、一个soft raid 设备;
3、一个LVM的逻辑卷;
4、一个EVMS(Enterprise Volume Management System,企业卷管理系统)的卷;
5、其他任何的块设备。
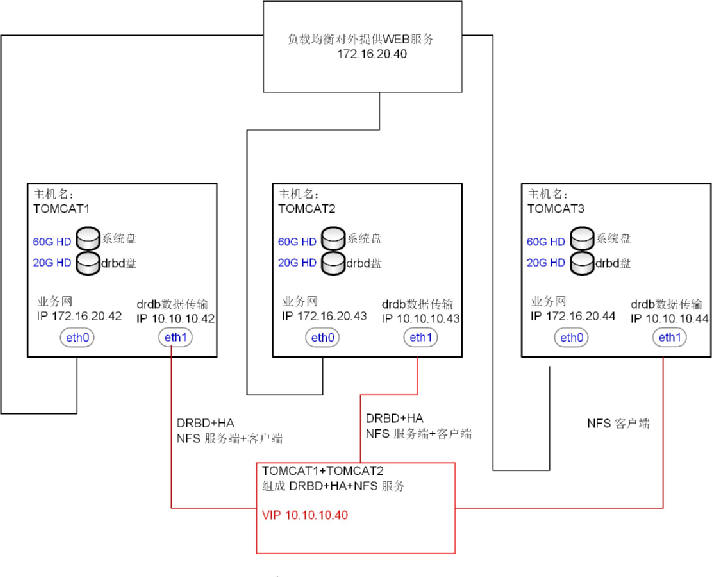
2、基于DRBD的解决方案
从互联网上也搜索到两个比较成功且适合上面应用场景的案例
DRBD+Heartbeat+NFS文件共享存储架构(主从模式)
http://blog.chinaunix.net/uid-25266990-id-3803277.html
DRBD使用gfs2,cman实现双主分布式文件存储方案
http://blog.sae.sina.com.cn/archives/3609
2.1搭建实验环境了
所需要的软件
REHL 6.4
drbd-8.4.6.tar.gz
drbd-utils-8.9.3.tar.gz (注意:drbd和drbd-utils的版本要对应起来)
2.2安装操作系统,配置IP地址,关闭防火墙,selinux 关闭NetworkManager,修改/etc/hosts,配置YUM (三台机器都需要操作)
2.2.1安装操作系统
省略
2.2.2配置IP地址
省略
由于我是虚拟机环境中测试,share2和share3均是直接克隆而来
克隆之后得到的机器需要修改的地方
计算机名 vi /etc/sysconfig/network
IP地址vi /etc/sysconfig/network-scripts/ifcfg-eth0
Udev 网卡绑定文件 vi /etc/udev/rules.d/70-persistent-net.rules
删除原来的网卡绑定,并修改
如下图:

2.2.3防火墙等配置
#vi /etc/selinux/config
确认里面的SELINUX字段的值是disabled,如果不是则改为disabled。
service iptables stop
service ip6tables stop
service NetworkManager stop
chkconfig iptables off
chkconfig ip6tables off
chkconfig NetworkManager off
2.2.4 hosts 文件配置
vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.16.20.42 share1
172.16.20.43 share2
172.16.20.44 share3
10.10.10.42 share1-drbd
10.10.10.43 share2-drbd
10.10.10.44 share3-drbd
2.2.5 配置yum
vi /etc/yum.repos.d/rhel-source.repo
[rhel-source]
name=Red Hat Enterprise Linux $releasever - $basearch - Source
baseurl=ftp://ftp.redhat.com/pub/redhat/linux/enterprise/$releasever/en/os/SRPMS/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
[rhel-source-beta]
name=Red Hat Enterprise Linux $releasever Beta - $basearch - Source
baseurl=ftp://ftp.redhat.com/pub/redhat/linux/beta/$releasever/en/os/SRPMS/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-beta,file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-releae
新增加如下内容:
我在内网服务器上新建了一个简单的HTTP服务器作为源地址

刷新yum缓存,<-没有缓存的情况下可能会报目录不存在的错误,无视
yum clean all
yum makecache
3安装drbd(share1和2上操作)
3.1 准备编译环境
yum -y install gcc make automake autoconf flex rpm-build kernel-devel
3.2 上传解压源文件
利用xftp 把 drbd-8.4.6.tar.gz,drbd-utils-8.9.3.tar.gz 两个压缩包上传到
Share 的/usr/local/src/ 目录下
如有没有请新建,命令如下
mkdir –p /usr/local/src/
解压两个包
tar drbd-8.4.6.tar.gz
tar -zxf drbd-8.4.6.tar.gz
3.3 准备编译安装
开始编译安装drbd,和8.4.5之前版本有所不同,这里不用./configure,直接make就可以了
./configure --prefix=/usr/local/drbd --with-km --with-heartbeat --sysconfdir=/etc/
3.3.1先查看内核版本
ll -d /usr/src/kernels/2.6.32-358.el6.x86_64/
3.3.2 编译
cd /usr/local/src/ drbd-8.4.6
make KDIR=/usr/src/kernels/2.6.32-358.el6.x86_64/
3.3.3安装
make install
3.3.4加载模块
modprobe drbd
lsmod | grep drbd
drbd 376868 0
libcrc32c 1246 1 drbd
3.3.5编译安装drbd-utils
----------------------------
cd /usr/local/src/drbd-utils-8.9.3
这里用了--without-83support,因为安装的是8.4以上版本
/configure --prefix=/usr/local/drbd-utils-8.9.3 --without-83support
make
make install
安装成功后drbd相关的工具(drbdadm,drbdsetup)被安装到/usr/local/drbd-utils-8.9.3/etc/sbin目录下
#cp /usr/local/drbd/etc/rc.d/init.d/drbd-utils-8.9.3 /etc/rc.d/init.d/
#chkconfig --add drbd
#chkconfig --level 2345 drbd on
#链接drbd的命令到系统命令路径
ln -s /usr/local/drbd-utils-8.9.3/sbin/* /usr/bin/
3.4.设置drbd.conf配置文件
详细配置说明请参考
http://www.itnose.net/detail/6272989.html
本次编译安装配置文件位置:/usr/local/drbd-utils-8.9.3/etc/
#vi /usr/local/drbd-utils-8.9.3/etc/drbd.conf
#include "drbd.d/global_common.conf";
#include "drbd.d/*.res";
global {
usage-count no;
}
common {
syncer { rate 1000M; }
}
resource r0 {
protocol C;
startup {
wfc-timeout 120;
degr-wfc-timeout 120;
}
disk {
on-io-error detach;
}
net{
timeout 60;
connect-int 10;
ping-int 10;
max-buffers 2048;
max-epoch-size 2048;
}
on share1{
device /dev/drbd0;
disk /dev/sdb1;
address 10.10.10.42:7788;
meta-disk internal;
}
on share2{
device /dev/drbd0;
disk /dev/sdb1;
address 10.10.10.43:7788;
meta-disk internal;
}
}
3.5.初始化资源
两台机器上分别初始化r0资源,创建DRBD分区
准备初始化之前,需要分别在2个主机上的 空白分区上创建相应的元数据保存的数据块:
常见之前现将两块空白分区彻底清除数据,分别在两个主机上执行
dd if=/dev/zero of=/dev/sdb1 bs=1M count=128 (两台机器上都运行)
drbdadm -c /etc/drbd.conf create-md all
或
drbdadm -c /etc/drbd.conf create-md r0
如有有报错请检查配置文件。
3.6启动两个节点drbd
mkdir -p /usr/local/drbd/var/run/drbd
#/etc/init.d/drbd start
3.7 查看状态:
#/etc/init.d/drbd status
drbd driver loaded OK; device status:
version: 8.4.6 (api:1/proto:86-101)
GIT-hash: 833d830e0152d1e457fa7856e71e11248ccf3f70 build by root@db01.mysql.com, 2015-06-24 13:47:15
m:res cs ro ds p mounted fstype
0:r0 Connected Secondary/Secondary Inconsistent/Inconsistent C
cs:表示连接状态
ro: 表示主从关系 上面的表示都为从
ds:硬盘状态信息 上面表示已经实时同步中,Inconsistent:不一致
# cat /proc/drbd
version: 8.4.6 (api:1/proto:86-101)
GIT-hash: 833d830e0152d1e457fa7856e71e11248ccf3f70 build by root@db01.mysql.com, 2015-06-24 13:47:15
0: cs:Connected ro:Primary/Secondary ds:UpToDate/UpToDate C r-----
ns:40088 nr:0 dw:0 dr:40248 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0
# drbd-overview
0:r0/0 Connected Secondary/Secondary Inconsistent/Inconsistent
3.7.1 查看版本
#cat /proc/drbd
3.7.2 查看位置
whereis drbd
3.8.操作
3.8.1 设置节点为主节点
第1步:设置主从第一次执行
#drbdadm -- --overwrite-data-of-peer primary all
第2步:第一次执行后平常执行下面两个其中一个命令
#drbdadm primary --force r0
#drbdadm primary all
第3步:设置当前节点为主节点
# cat /proc/drbd
version: 8.4.6 (api:1/proto:86-101)
GIT-hash: 833d830e0152d1e457fa7856e71e11248ccf3f70 build by root@db01.mysql.com, 2015-06-24 13:47:15
0: cs:Connected ro:Primary/Secondary ds:UpToDate/UpToDate C r-----
ns:40088 nr:0 dw:0 dr:40248 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0
注意主备节点第一次同步需要一定时间。
#drbdadm primary --force r0
# cat /proc/drbd
version: 8.4.6 (api:1/proto:86-101)
GIT-hash: 833d830e0152d1e457fa7856e71e11248ccf3f70 build by root@db01.mysql.com, 2015-06-24 13:47:15
0: cs:Connected ro:Primary/Secondary ds:UpToDate/UpToDate C r-----
ns:40088 nr:0 dw:0 dr:40248 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0
说明:ro状态变为ro:Primary/Secondary;ds状态为:UpToDate/UpToDate(inconsisten) 即"实时/实时(不一致)"
3.8.2 磁盘格式化(只对primary节点格式化)
#drbd-overview
0:r0/0 Connected Primary/Secondary UpToDate/UpToDate
同步完毕之后,就可以对空白磁盘格式化了.
#mkfs.ext4 /dev/drbd0
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=1024 (log=0)
Fragment size=1024 (log=0)
Stride=0 blocks, Stripe width=0 blocks
10040 inodes, 40088 blocks
2004 blocks (5.00%) reserved for the super user
First data block=1
Maximum filesystem blocks=41156608
5 block groups
8192 blocks per group, 8192 fragments per group
2008 inodes per group
Superblock backups stored on blocks:
8193, 24577
Writing inode tables: done
Creating journal (4096 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 33 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
3.8.3挂载DRBD分区到本地(只能在primary节点上挂载)
# mkdir /drbd_data
# mount /dev/drbd0 /drbd_data/
# cd /drbd_data/
#ls
3.8.4 常见命令
查看资源角色(前面代表当前资源角色)
# drbdadm role r0
Primary/Secondary
查看资源连接状态
#drbdadm cstate r0
Connected
查看硬盘数据状态
# drbdadm dstate r0
UpToDate/UpToDate
注意事项
1.主备服务器同步的两个分区大小最好相同(网上没有关于分区大小是否一定要相同的确切说法)
2.开始同步两个节点的磁盘,需要一定时间,在同步完成前,不要重启,否则会重新同步。
3.挂载之前一定要先切换当前节点为主节点
4.两个节点中,同一时刻只能有一台处于primary状态,另一台处于secondary状态。
5.处于从节点(secondary)状态的服务器不能加载drbd块设备
6.将主节点切换为从节点之前要先卸载
7.一台主机切换为主节点之前,要确保另一台主机已切换为从节点。
3.9.测试DRBD数据镜像
3.9.1格式化挂载磁盘
#mkfs.ext4 /dev/drbd0
# mkdir /drbd_data
# mount /dev/drbd0 /drbd_data/
# cd /drbd_data/
3.9.2 生成测试数据
#touch /drbd_data/test.txt
#dd if=/dev/zero of=/drbd_data/test.tmp bs=1M count=20
# drbdadm dstate r0
UpToDate/UpToDate
3.9.3 将主节点drbd的状态变为从
# drbdadm role r0
Primary/Secondary
#umount /drbd_data
#drbdadm secondary all
# drbdadm role r0
Secondary/Secondary
3.9.4 在从节点上进行挂载
#drbdadm role r0
Secondary/Secondary
#drbdadm primary all
#drbdadm role r0
Primary/Secondary
#mkdir /drbd_data
#mount /dev/drbd0 /drbd_data/
# ls -ls /drbd_data/
total 20493
12 drwx------ 2 root root12288 Jun 24 17:02 lost+found
20481 -rw-r--r-- 1 root root 20971520 Jun 24 17:20 test.tmp
测试成功.
3.10手动修复裂脑问题
问题描述:模拟主节点网络断开,辅节点将会转换角色到Primay。之后恢复主节点网
络,裂脑问题出现,原因是DRBD检测到两台服务器都为Primary。
主节点/proc/drbd文件中显示的网络状况为:cs:WFConnection
辅节点/proc/drbd文件中显示的网络状况为:cs:StandAlone
或
主节点/proc/drbd文件中显示的网络状况为:cs:StandAlone
辅节点/proc/drbd文件中显示的网络状况为:cs:StandAlone
解决方法:a. 登录辅节点服务器,将其角色改为Secondary
drbdadm secondary all
b. 在辅助节点上,断开连接
drbdadm disconnect all
c. 在辅节点上,丢弃本地磁盘上的所有数据,并连接资源
drbdadm -- --discard-my-data connect all
d. 登录主节点服务器,观察其连接状态,如果其状态仍为
StandAlone,指行下列命令
drbdadm connect all
3.11更换主节点硬盘操作
1. 关闭主节点服务器,临时将辅节点提升为Primary
2. 为主节点替换新硬盘,并开机
3. 主节点正常启动后,关闭drbd进程
/etc/init.d/drbd stop
4. 对硬盘进行格式化,切忌不要为其创建EXT3文件系统
5. 加载drbd模块,并附加本地磁盘到drbd驱动
modprobe drbd
6. 启动drbd进程
/etc/init.d/drbd start
7. 将辅节点角色从Primary转为Secondary
drbdadmin secondary all
8. 主节点角色设为Primary
drbdadm primary all
9. 挂载drbd驱动到挂载目录
mount /dev/drbd1 /mnt/drbd1
4、安装配置NFS
4.1 安装NFS(share1和2都需要)
使用"yum groupinstall "NFS file server""命令来安装NFS file server。
它比使用yum install nfs-utils命令多安装了一个nfs4-acl-tools RPM包。
chkconfig --list
将rpcbind和nfs都设为自动启动
chkconfig rpcbind on
chkconfig nfs on
启动rpcbind
service rpcbind start
之后才能成功启动nfs
service nfs start
一定要先启动rpcbind,然后再启动nfs,不然NFS quotas和NFS daemon都将启动失败
4.2 配置NFS(share1和2都需要)
vi /etc/exports
/drbd_data/ 10.10.10.42(rw,sync,no_root_squash,all_squash,anonuid=0,anongid=0)
/drbd_data/ 10.10.10.43(rw,sync,no_root_squash,all_squash,anonuid=0,anongid=0)
/drbd_data/ 10.10.10.44(rw,sync,no_root_squash,all_squash,anonuid=0,anongid=0)
由于是到时候3台机器都有对NFS目录进行频繁的读写操作,这里的意思是
10.10.10.42-44 的机器不管什么用户登录都将获得drbd_date 目录的root权限
showmount -e (两边都配置完后,查看一下共享的文件是否已经可以看到
如果提示错误可以重启一下NFS 服务
service nfs restart
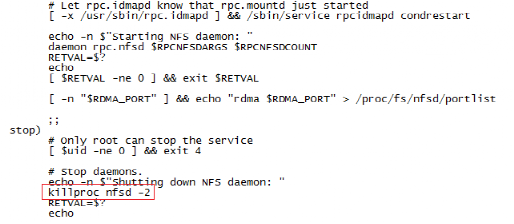
vi /etc/init.d/nfs (把这个文件的值改一下)
约148行添加 shift+n 然后输入148转到148行
killproc nfsd -9#将/etc/init.d/nfs 脚本中的stop 部分中的killproc#nfsd -2 修改为 -9
同时要启动锁机制,因为同时有两个节点要使用同一份数据,所以需要有总裁,这个尤其是在NFS给mysql 用的时候是必须要用的,对于论坛或网站,要看情况,如果存在对同一文件同时修改的时候必须要启动NFS锁机制,如果没有这种情况,那么建议不要启动,启动 了会降低NFS的性能:/sbin/rpc.lockdecho “/sbin/rpc.lockd” >>/etc/rc.local
5安装Heartbeat
5.1 下载安装包
由于实验机器没法上网 从网上下载Heartbeat的安装包并使用Xftp工具上传到share1和2
下载地址:
解压出来的包
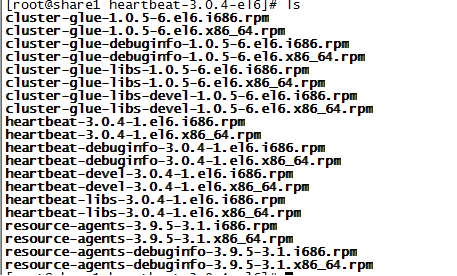
开始安装,注意一定要安顺序
1、rpm -ivh cluster-glue-debuginfo-1.0.5-6.el6.x86_64.rpm
2、rpm -ivh cluster-glue-libs-1.0.5-6.el6.x86_64.rpm cluster-glue-libs-devel-1.0.5-6.el6.x86_64.rpm cluster-glue-1.0.5-6.el6.x86_64.rpm
(3个包一定要一起安装,不然会报很多错误)

缺少 per-TimeDate 包使用yum 安装
yum -y install perl-TimeDate
rpm -ivh cluster-glue-libs-1.0.5-6.el6.x86_64.rpm cluster-glue-libs-devel-1.0.5-6.el6.x86_64.rpm cluster-glue-1.0.5-6.el6.x86_64.rpm
3、rpm -ivh resource-agents-debuginfo-3.9.5-3.1.x86_64.rpm resource-agents-3.9.5-3.1.x86_64.rpm

报fsck.xfs 是缺少xfsprogs包
下载地址:http://mirror.centos.org/centos/6/os/x86_64/Packages/xfsprogs-3.1.1-16.el6.x86_64.rpm
下载之后上传到 /mnt目录下
rpm -ivh xfsprogs-3.1.1-16.el6.x86_64.rpm
rpm -ivh resource-agents-debuginfo-3.9.5-3.1.x86_64.rpm resource-agents-3.9.5-3.1.x86_64.rpm
4、rpm -ivh heartbeat-debuginfo-3.0.4-1.el6.x86_64.rpm
5、rpm -ivh heartbeat-3.0.4-1.el6.x86_64.rpm heartbeat-devel-3.0.4-1.el6.x86_64.rpm heartbeat-libs-3.0.4-1.el6.x86_64.rpm

缺少PYXML 包
yum -y install PyXML
rpm -ivh heartbeat-3.0.4-1.el6.x86_64.rpm heartbeat-devel-3.0.4-1.el6.x86_64.rpm heartbeat-libs-3.0.4-1.el6.x86_64.rpm
安装完后会自动建立用户hacluster和组haclient确保两个节点上hacluster用户的的UID和GID相同在两台节点上分别执行:
cat /etc/passwd | grep hacluster
结果相同即可
5.2配置heartbeat
在从节点上也作同样的操作
配置主节点的heartbeatHeartbeat的主要配置文件有ha.cf、haresources、authkeys,均在/etc/ha.d目录 下,在通过yum安装Heartbeat后,默认并没有这三个文件,可从解压的源码目录中找到,这里手动创建并编辑。
5.2.1主配置文件:ha.cf
配置heartbeat的检测机制本次实例中,内容设置如下:
debugfile /var/log/ha-debu
logfile /var/log/ha-log
logfacility local0
keepalive 2
warntime 10
deadtime 30
initdead 120
hopfudge 1
udpport 694
bcast eth1
ucast eth1 10.10.10.43 (从机配置 10.10.10.42)
auto_failback on
node share1
node share2
ping 172.16.20.254
watchdog /dev/watchdog
respawn root /usr/lib64/heartbeat/ipfail
apiauth ipfail gid=root uid=root
说明:
debugfile /var/log/ha-debug #用于记录heartbeat的调试信息
logfile /var/log/ha-log #用于记录heartbeat的日志信息
logfacility local0 #系统日志级别
keepalive 2 #设定心跳(监测)间隔时间,默认单位为秒
warntime 10 ##警告时间,通常为deadtime时间的一半
deadtime 30 # 超出30秒未收到对方节点的心跳,则认为对方已经死亡
initdead 120 #网络启动时间,至少为deadtime的两倍。
hopfudge 1 #可选项:用于环状拓扑结构,在集群中总共跳跃节点的数量
udpport 694 #使用udp端口694 进行心跳监测
bcast eth1
ucast eth1 10.10.10.43 #采用单播,进行心跳监测,IP为对方主机
IPauto_failback on #on表示当拥有该资源的属主恢复之后,资源迁移到属主上
node share1 #设置集群中的节点,节点名须与uname –n相匹配
node share2 #节点2
ping 172.16.20.254 #ping集群以外的节点,这里是网关,用于检测网络的连接性
watchdog /dev/watchdog #看门狗。如果本节点在超过1分钟后还没有发出心跳,那么本节点自动重启
respawn root /usr/lib64/heartbeat/ipfail
apiauth ipfail gid=root uid=root #设置所指定的启动进程的权限
注:heartbeat的两台主机分别为主节点和从节点。主节点在正常情况下占用资源并运行所有的服务,遇到故障时把资源交给从节点并由从节点运行服务。
5.2.2配置haresourcesha.cf
资源文件haresourcesha.cf文件设置了heartbeat的检验机制,没有 执行机制。Haresources用来设置当主服务器出现问题时heartbeat的执行机制。 其内容为:当主服务器宕机后,该怎样进行切换操作。切换内容通常有IP地址的切换、服务的切换、共享存储的切换,从而使从服务器具有和主服务器同样的 IP、SERVICE、SHARESTORAGE,从而使client没有察觉。在两个HA节点上该文件必须完全一致。本次实例中,内容设置如下:
vi /etc/ha.d/haresources
share1 IPaddr::10.10.10.40/24/eth1 dbrd_swtich killnfsd
注释:上面那行
share1 定义manager为heartbeat的主机
10.10.10.40 定义对外服务的IP地址,这个IP自动在主从机之间切换
drbddisk::r0 定义使用的drbd资源
Filesystem::/dev/drbd0::/drbd_data::ext4 定义挂载文件系统
portmap nfs 定义其他需要切换的服务(用空格隔开)
5.2.3认证文件authkeys
认证文件authkeys用于配置心跳的加密方式,该文件主要是用于集群中两个节点的认 证,采用的算法和密钥在集群中节点上必须相同,目前提供了3种算法:md5,sha1和crc。其中crc不能够提供认证,它只能够用于校验数据包是否损 坏,而sha1,md5需要一个密钥来进行认证。本次实例中,内容设置如下:
# dd if=/dev/random bs=512 count=1 |openssl md5 (随机产生一个参数用md5加密)
5.2.4文件系统切换脚本
vi /etc/ha.d/resource.d/dbrd_swtich

|
|
vi /etc/ha.d/resource.d/killnfsd
chmod a+x /etc/ha.d/resource.d/killnfsd
chmod a+x /etc/ha.d/resource.d/ dbrd_swtich
5.2.5修改备机相关配置:
Drbd备机和Drbd主机配置基本相同。修改备机上/etc/ha.d/ha.cf 中的ucast eth1为对方的IP
5.2.6 Heartbeat测试
1.查看两边的状态
两边同时启动heartbeat 观察日志
share1上 HA的日志:
|
[Nov 30 18:25:39 share1 heartbeat: [4459]: info: Pacemaker support: false Nov 30 18:25:39 share1 heartbeat: [4459]: WARN: Logging daemon is disabled --enabling logging daemon is recommended Nov 30 18:25:39 share1 heartbeat: [4459]: info: ************************** Nov 30 18:25:39 share1 heartbeat: [4459]: info: Configuration validated. Starting heartbeat 3.0.4 Nov 30 18:25:39 share1 heartbeat: [4460]: info: heartbeat: version 3.0.4 Nov 30 18:25:39 share1 heartbeat: [4460]: info: Heartbeat generation: 1448645678 Nov 30 18:25:39 share1 heartbeat: [4460]: info: glib: UDP Broadcast heartbeat started on port 694 (694) interface eth1 Nov 30 18:25:39 share1 heartbeat: [4460]: info: glib: UDP Broadcast heartbeat closed on port 694 interface eth1 - Status: 1 Nov 30 18:25:39 share1 heartbeat: [4460]: info: glib: ucast: write socket priority set to IPTOS_LOWDELAY on eth1 Nov 30 18:25:39 share1 heartbeat: [4460]: info: glib: ucast: bound send socket to device: eth1 Nov 30 18:25:39 share1 heartbeat: [4460]: info: glib: ucast: bound receive socket to device: eth1 Nov 30 18:25:39 share1 heartbeat: [4460]: info: glib: ucast: started on port 694 interface eth1 to 10.10.10.43 Nov 30 18:25:39 share1 heartbeat: [4460]: info: glib: ping heartbeat started. Nov 30 18:25:39 share1 heartbeat: [4460]: info: G_main_add_TriggerHandler: Added signal manual handler Nov 30 18:25:39 share1 heartbeat: [4460]: info: G_main_add_TriggerHandler: Added signal manual handler Nov 30 18:25:39 share1 heartbeat: [4460]: info: G_main_add_SignalHandler: Added signal handler for signal 17 Nov 30 18:25:39 share1 heartbeat: [4460]: info: Local status now set to: 'up' Nov 30 18:25:39 share1 heartbeat: [4460]: info: Link share1:eth1 up. Nov 30 18:25:40 share1 heartbeat: [4460]: info: Link 172.16.20.254:172.16.20.254 up. Nov 30 18:25:40 share1 heartbeat: [4460]: info: Status update for node 172.16.20.254: status ping Nov 30 18:25:40 share1 heartbeat: [4460]: info: Link share2:eth1 up. Nov 30 18:25:40 share1 heartbeat: [4460]: info: Status update for node share2: status active harc(default)[4472]: 2015/11/30_18:25:40 info: Running /etc/ha.d//rc.d/status status Nov 30 18:25:41 share1 heartbeat: [4460]: info: Comm_now_up(): updating status to active Nov 30 18:25:41 share1 heartbeat: [4460]: info: Local status now set to: 'active' Nov 30 18:25:41 share1 heartbeat: [4460]: info: Starting child client "/usr/lib64/heartbeat/ipfail" (0,0) Nov 30 18:25:41 share1 heartbeat: [4490]: info: Starting "/usr/lib64/heartbeat/ipfail" as uid 0 gid 0 (pid 4490) Nov 30 18:25:41 share1 heartbeat: [4460]: info: remote resource transition completed. Nov 30 18:25:41 share1 heartbeat: [4460]: info: remote resource transition completed. Nov 30 18:25:41 share1 heartbeat: [4460]: info: Local Resource acquisition completed. (none) Nov 30 18:25:42 share1 heartbeat: [4460]: info: share2 wants to go standby [foreign] Nov 30 18:25:43 share1 heartbeat: [4460]: info: standby: acquire [foreign] resources from share2 Nov 30 18:25:43 share1 heartbeat: [4493]: info: acquire local HA resources (standby). ResourceManager(default)[4506]: 2015/11/30_18:25:43 info: Acquiring resource group: share1 IPaddr::10.10.10.40/24/eth1 drbd_swtich killnfsd /usr/lib/ocf/resource.d//heartbeat/IPaddr(IPaddr_10.10.10.40)[4534]: 2015/11/30_18:25:44 INFO: Resource is stopped ResourceManager(default)[4506]: 2015/11/30_18:25:44 info: Running /etc/ha.d/resource.d/IPaddr 10.10.10.40/24/eth1 start IPaddr(IPaddr_10.10.10.40)[4619]: 2015/11/30_18:25:44 INFO: Using calculated netmask for 10.10.10.40: 255.255.255.0 IPaddr(IPaddr_10.10.10.40)[4619]: 2015/11/30_18:25:44 INFO: eval ifconfig eth1:0 10.10.10.40 netmask 255.255.255.0 broadcast 10.10.10.255 /usr/lib/ocf/resource.d//heartbeat/IPaddr(IPaddr_10.10.10.40)[4593]: 2015/11/30_18:25:44 INFO: Success (先获得虚拟IP) ResourceManager(default)[4506]: 2015/11/30_18:25:44 info: Running /etc/ha.d/resource.d/drbd_swtich start (然后启动drbd_swich脚本) 这里舍弃掉了系统自带NFS脚本。而是自己写了一个脚本代替,脚本很简单,没有 start 等参数,日志里没有运行显示的记录 Nov 30 18:25:47 share1 ipfail: [4490]: info: Ping node count is balanced. Nov 30 18:25:49 share1 heartbeat: [4493]: info: local HA resource acquisition completed (standby). Nov 30 18:25:49 share1 heartbeat: [4460]: info: Standby resource acquisition done [foreign]. Nov 30 18:25:49 share1 heartbeat: [4460]: info: Initial resource acquisition complete (auto_failback) Nov 30 18:25:49 share1 heartbeat: [4460]: info: remote resource transition completed.
|
share1网络状态
|
[root@share1 resource.d]# ifconfig eth0 Link encap:Ethernet HWaddr 00:50:56:BB:A5:6C inet addr:172.16.20.42 Bcast:172.16.20.255 Mask:255.255.255.0 inet6 addr: fe80::250:56ff:febb:a56c/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:167795 errors:0 dropped:0 overruns:0 frame:0 TX packets:124079 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:24655414 (23.5 MiB) TX bytes:17597452 (16.7 MiB)
eth1 Link encap:Ethernet HWaddr 00:50:56:BB:B4:9A inet addr:10.10.10.42 Bcast:10.10.10.255 Mask:255.255.255.0 inet6 addr: fe80::250:56ff:febb:b49a/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:324495 errors:0 dropped:0 overruns:0 frame:0 TX packets:324476 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:70976149 (67.6 MiB) TX bytes:70918820 (67.6 MiB)
eth1:0 Link encap:Ethernet HWaddr 00:50:56:BB:B4:9A inet addr:10.10.10.40 Bcast:10.10.10.255 Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 虚拟IP在share1节点上 |
share1 drbd状态
|
[root@share1 ~]# service drbd status drbd driver loaded OK; device status: version: 8.4.6 (api:1/proto:86-101) GIT-hash: 833d830e0152d1e457fa7856e71e11248ccf3f70 build by root@share2, 2015-11-25 19:20:50 m:res cs ro ds p mounted fstype 0:r0 Connected Primary/Secondary UpToDate/UpToDate C /drbd_data ext4 [root@share1 ~]# 本节点为主节点,对端为冗余节点,数据状态为同步,已挂载 |
share1文件系统状态
|
[root@share1 ~]# mount /dev/mapper/vg_share1-lv_root on / type ext4 (rw) proc on /proc type proc (rw) sysfs on /sys type sysfs (rw) devpts on /dev/pts type devpts (rw,gid=5,mode=620) tmpfs on /dev/shm type tmpfs (rw,rootcontext="system_u:object_r:tmpfs_t:s0") /dev/sda1 on /boot type ext4 (rw) none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw) sunrpc on /var/lib/nfs/rpc_pipefs type rpc_pipefs (rw) nfsd on /proc/fs/nfsd type nfsd (rw) /dev/drbd0 on /drbd_data type ext4 (rw) drbd挂载在share1节点上 |
share2上 HA的日志:
|
[root@share2 ~]# tail -f /var/log/ha-log Nov 30 18:56:27 share2 heartbeat: [21920]: info: remote resource transition completed. Nov 30 18:56:27 share2 heartbeat: [21920]: info: No pkts missing from share1! Nov 30 18:56:27 share2 heartbeat: [21920]: info: Other node completed standby takeover of foreign resources. Nov 30 18:56:28 share2 ipfail: [21934]: info: No giveup timer to abort. Nov 30 18:56:32 share2 heartbeat: [21920]: info: share1 wants to go standby [foreign] Nov 30 18:56:33 share2 heartbeat: [21920]: info: standby: acquire [foreign] resources from share1 Nov 30 18:56:33 share2 heartbeat: [24367]: info: acquire local HA resources (standby). Nov 30 18:56:33 share2 heartbeat: [24367]: info: local HA resource acquisition completed (standby). Nov 30 18:56:33 share2 heartbeat: [21920]: info: Standby resource acquisition done [foreign]. Nov 30 18:56:33 share2 heartbeat: [21920]: info: remote resource transition completed. |
share2网络状态
|
[root@share2 ~]# ifconfig eth0 Link encap:Ethernet HWaddr 00:50:56:BB:F2:C7 inet addr:172.16.20.43 Bcast:172.16.20.255 Mask:255.255.255.0 inet6 addr: fe80::250:56ff:febb:f2c7/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:172458 errors:0 dropped:0 overruns:0 frame:0 TX packets:127087 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:25335098 (24.1 MiB) TX bytes:17932028 (17.1 MiB)
eth1 Link encap:Ethernet HWaddr 00:50:56:BB:B6:41 inet addr:10.10.10.43 Bcast:10.10.10.255 Mask:255.255.255.0 inet6 addr: fe80::250:56ff:febb:b641/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:330720 errors:0 dropped:0 overruns:0 frame:0 TX packets:332131 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:72900847 (69.5 MiB) TX bytes:73007469 (69.6 MiB) |
Share2 drbd状态
|
[root@share2 ~]# service drbd status drbd driver loaded OK; device status: version: 8.4.6 (api:1/proto:86-101) GIT-hash: 833d830e0152d1e457fa7856e71e11248ccf3f70 build by root@share2, 2015-11-25 19:20:50 m:res cs ro ds p mounted fstype 0:r0 Connected Secondary/Primary UpToDate/UpToDate C 本节点为冗余节点,对端为主节点,数据状态为同步,没有挂载 |
share2文件系统状态
|
[root@share2 ~]# mount /dev/mapper/vg_share1-lv_root on / type ext4 (rw) proc on /proc type proc (rw) sysfs on /sys type sysfs (rw) devpts on /dev/pts type devpts (rw,gid=5,mode=620) tmpfs on /dev/shm type tmpfs (rw,rootcontext="system_u:object_r:tmpfs_t:s0") /dev/sda1 on /boot type ext4 (rw) none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw) sunrpc on /var/lib/nfs/rpc_pipefs type rpc_pipefs (rw) nfsd on /proc/fs/nfsd type nfsd (rw) |
在share3 上挂载目录
mount 10.10.10.40:/drbd_data /mnt/share
创建一个文件 并写入内容
vi /mnt/share/share3.txt 注意不要直接进入/mnt/share 目录操作,我进去目录之后再进行操作,切换HA的时候还要退出来再进去。
share1上停止HA服务
|
[root@share1 ~]# service heartbeat stop |
share1上 HA的日志:
|
Nov 30 19:18:10 share1 heartbeat: [5509]: info: Heartbeat shutdown in progress. (5509) Nov 30 19:18:10 share1 heartbeat: [6126]: info: Giving up all HA resources. ResourceManager(default)[6139]: 2015/11/30_19:18:10 info: Releasing resource group: share1 IPaddr::10.10.10.40/24/eth1 drbd_swtich killnfsd ResourceManager(default)[6139]: 2015/11/30_19:18:10 info: Running /etc/ha.d/resource.d/killnfsd stop 先关闭NFS ResourceManager(default)[6139]: 2015/11/30_19:18:11 info: Running /etc/ha.d/resource.d/drbd_swtich stop 咋关闭drbd ResourceManager(default)[6139]: 2015/11/30_19:18:11 info: Running /etc/ha.d/resource.d/IPaddr 10.10.10.40/24/eth1 stop 最后卸载虚IP IPaddr(IPaddr_10.10.10.40)[6389]: 2015/11/30_19:18:11 INFO: ifconfig eth1:0 down /usr/lib/ocf/resource.d//heartbeat/IPaddr(IPaddr_10.10.10.40)[6360]: 2015/11/30_19:18:11 INFO: Success Nov 30 19:18:11 share1 heartbeat: [6126]: info: All HA resources relinquished. Nov 30 19:18:12 share1 heartbeat: [5509]: WARN: 1 lost packet(s) for [share2] [3113:3115] Nov 30 19:18:12 share1 heartbeat: [5509]: info: No pkts missing from share2! Nov 30 19:18:12 share1 heartbeat: [5509]: info: killing /usr/lib64/heartbeat/ipfail process group 5539 with signal 15 Nov 30 19:18:14 share1 heartbeat: [5509]: info: killing HBWRITE process 5518 with signal 15 Nov 30 19:18:14 share1 heartbeat: [5509]: info: killing HBREAD process 5519 with signal 15 Nov 30 19:18:14 share1 heartbeat: [5509]: info: killing HBFIFO process 5513 with signal 15 Nov 30 19:18:14 share1 heartbeat: [5509]: info: killing HBWRITE process 5514 with signal 15 Nov 30 19:18:14 share1 heartbeat: [5509]: info: killing HBREAD process 5515 with signal 15 Nov 30 19:18:14 share1 heartbeat: [5509]: info: killing HBWRITE process 5516 with signal 15 Nov 30 19:18:14 share1 heartbeat: [5509]: info: killing HBREAD process 5517 with signal 15 Nov 30 19:18:14 share1 heartbeat: [5509]: info: Core process 5519 exited. 7 remaining Nov 30 19:18:14 share1 heartbeat: [5509]: info: Core process 5518 exited. 6 remaining Nov 30 19:18:14 share1 heartbeat: [5509]: info: Core process 5516 exited. 5 remaining Nov 30 19:18:14 share1 heartbeat: [5509]: info: Core process 5513 exited. 4 remaining Nov 30 19:18:14 share1 heartbeat: [5509]: info: Core process 5517 exited. 3 remaining Nov 30 19:18:14 share1 heartbeat: [5509]: info: Core process 5514 exited. 2 remaining Nov 30 19:18:14 share1 heartbeat: [5509]: info: Core process 5515 exited. 1 remaining Nov 30 19:18:14 share1 heartbeat: [5509]: info: share1 Heartbeat shutdown complete. |
share1网络状态
|
[root@share1 resource.d]# ifconfig eth0 Link encap:Ethernet HWaddr 00:50:56:BB:A5:6C inet addr:172.16.20.42 Bcast:172.16.20.255 Mask:255.255.255.0 inet6 addr: fe80::250:56ff:febb:a56c/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:167795 errors:0 dropped:0 overruns:0 frame:0 TX packets:124079 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:24655414 (23.5 MiB) TX bytes:17597452 (16.7 MiB)
eth1 Link encap:Ethernet HWaddr 00:50:56:BB:B4:9A inet addr:10.10.10.42 Bcast:10.10.10.255 Mask:255.255.255.0 inet6 addr: fe80::250:56ff:febb:b49a/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:324495 errors:0 dropped:0 overruns:0 frame:0 TX packets:324476 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:70976149 (67.6 MiB) TX bytes:70918820 (67.6 MiB) Eth1:1 消失了 |
share1文件系统状态
|
[root@share1 ~]# mount /dev/mapper/vg_share1-lv_root on / type ext4 (rw) proc on /proc type proc (rw) sysfs on /sys type sysfs (rw) devpts on /dev/pts type devpts (rw,gid=5,mode=620) tmpfs on /dev/shm type tmpfs (rw,rootcontext="system_u:object_r:tmpfs_t:s0") /dev/sda1 on /boot type ext4 (rw) none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw) sunrpc on /var/lib/nfs/rpc_pipefs type rpc_pipefs (rw) nfsd on /proc/fs/nfsd type nfsd (rw) [root@share1 ~]# drdb的挂载也消失了 |
share1 drbd状态
|
[root@share1 ~]# service drbd status drbd driver loaded OK; device status: version: 8.4.6 (api:1/proto:86-101) GIT-hash: 833d830e0152d1e457fa7856e71e11248ccf3f70 build by root@share2, 2015-11-25 19:20:50 m:res cs ro ds p mounted fstype 0:r0 Connected Secondary/Primary UpToDate/UpToDate C [root@share1 ~]#本节点为冗余节点,对端为主节点,数据状态为同步,没有挂载 |
share2上 HA的日志:
|
Nov 30 19:18:13 share2 heartbeat: [24517]: info: No local resources [/usr/share/heartbeat/ResourceManager listkeys share2] to acquire. Nov 30 19:18:13 share2 heartbeat: [24516]: info: local HA resource acquisition completed (standby). Nov 30 19:18:13 share2 heartbeat: [21920]: info: Standby resource acquisition done [foreign]. 获得集群资源 harc(default)[24542]: 2015/11/30_19:18:13 info: Running /etc/ha.d//rc.d/status status mach_down(default)[24559]: 2015/11/30_19:18:13 info: Taking over resource group IPaddr::10.10.10.40/24/eth1 检测集群IP ResourceManager(default)[24586]: 2015/11/30_19:18:13 info: Acquiring resource group: share1 IPaddr::10.10.10.40/24/eth1 drbd_swtich killnfsd /usr/lib/ocf/resource.d//heartbeat/IPaddr(IPaddr_10.10.10.40)[24614]: 2015/11/30_19:18:13 INFO: Resource is stopped 集群资源停止 ResourceManager(default)[24586]: 2015/11/30_19:18:13 info: Running /etc/ha.d/resource.d/IPaddr 10.10.10.40/24/eth1 start 获得集群VIP IPaddr(IPaddr_10.10.10.40)[24699]: 2015/11/30_19:18:13 INFO: Using calculated netmask for 10.10.10.40: 255.255.255.0 IPaddr(IPaddr_10.10.10.40)[24699]: 2015/11/30_19:18:13 INFO: eval ifconfig eth1:0 10.10.10.40 netmask 255.255.255.0 broadcast 10.10.10.255 /usr/lib/ocf/resource.d//heartbeat/IPaddr(IPaddr_10.10.10.40)[24673]: 2015/11/30_19:18:13 INFO: Success 获得完毕 ResourceManager(default)[24586]: 2015/11/30_19:18:13 info: Running /etc/ha.d/resource.d/drbd_swtich start 运行drbd_switch脚本 获得drbd资源 mach_down(default)[24559]: 2015/11/30_19:18:14 info: /usr/share/heartbeat/mach_down: nice_failback: foreign resources acquired mach_down(default)[24559]: 2015/11/30_19:18:14 info: mach_down takeover complete for node share1. Nov 30 19:18:14 share2 heartbeat: [21920]: info: mach_down takeover complete. Nov 30 19:18:44 share2 heartbeat: [21920]: WARN: node share1: is dead Nov 30 19:18:44 share2 heartbeat: [21920]: info: Dead node share1 gave up resources. Nov 30 19:18:44 share2 ipfail: [21934]: info: Status update: Node share1 now has status dead Nov 30 19:18:45 share2 heartbeat: [21920]: info: Link share1:eth1 dead. Nov 30 19:18:46 share2 ipfail: [21934]: info: NS: We are still alive! Nov 30 19:18:46 share2 ipfail: [21934]: info: Link Status update: Link share1/eth1 now has status dead Nov 30 19:18:47 share2 ipfail: [21934]: info: Asking other side for ping node count. Nov 30 19:18:47 share2 ipfail: [21934]: info: Checking remote count of ping nodes. |
share2网络状态
|
[root@share2 ~]# ifconfig eth0 Link encap:Ethernet HWaddr 00:50:56:BB:F2:C7 inet addr:172.16.20.43 Bcast:172.16.20.255 Mask:255.255.255.0 inet6 addr: fe80::250:56ff:febb:f2c7/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:173430 errors:0 dropped:0 overruns:0 frame:0 TX packets:127840 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:25471729 (24.2 MiB) TX bytes:18037435 (17.2 MiB)
eth1 Link encap:Ethernet HWaddr 00:50:56:BB:B6:41 inet addr:10.10.10.43 Bcast:10.10.10.255 Mask:255.255.255.0 inet6 addr: fe80::250:56ff:febb:b641/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:332663 errors:0 dropped:0 overruns:0 frame:0 TX packets:334334 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:73907295 (70.4 MiB) TX bytes:73422553 (70.0 MiB)
eth1:0 Link encap:Ethernet HWaddr 00:50:56:BB:B6:41 inet addr:10.10.10.40 Bcast:10.10.10.255 Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 集群IP 转移到share2节点成功 |
share2 drbd状态
|
[root@share2 ~]# service drbd status drbd driver loaded OK; device status: version: 8.4.6 (api:1/proto:86-101) GIT-hash: 833d830e0152d1e457fa7856e71e11248ccf3f70 build by root@share2, 2015-11-25 19:20:50 m:res cs ro ds p mounted fstype 0:r0 Connected Primary/Secondary UpToDate/UpToDate C /drbd_data ext4 Drbd磁盘主切换成功并挂载 |
share2文件系统状态
|
[root@share2 ~]# mount /dev/mapper/vg_share1-lv_root on / type ext4 (rw) proc on /proc type proc (rw) sysfs on /sys type sysfs (rw) devpts on /dev/pts type devpts (rw,gid=5,mode=620) tmpfs on /dev/shm type tmpfs (rw,rootcontext="system_u:object_r:tmpfs_t:s0") /dev/sda1 on /boot type ext4 (rw) none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw) sunrpc on /var/lib/nfs/rpc_pipefs type rpc_pipefs (rw) nfsd on /proc/fs/nfsd type nfsd (rw) /dev/drbd0 on /drbd_data type ext4 (rw) 挂载drbd磁盘成功 |
NFS 状态
|
[root@share2 ~]# showmount -e Export list for share2: /drbd_data 10.10.10.44,10.10.10.43,10.10.10.42 NFS 目录共享成功 |
从HA的切换日志来看整个切换过程33秒,实际体验客户端的延时大概为1分钟。
服务启动的顺序,drbd让系统自动加载,heartbeat 放在/etc/rc.local里面,不然会出错,因为heartbeat会在drbd前面启动,你可以调整他们两的启动顺序。
6写在最后
这次实验居然用了差不多6天时间,网上找的文章大部分都不是很详细
比如关于brdb的安装。 版本分为8.4.5之前和之后安装区别太大了,我一开始找到的都是8.4.5之前的怎么安装怎么不对
HEARTBEAT的安装更是一个大坑接着一个大坑
比如几个包一定要同时安装,貌似就没有提醒。根据网上找到的教程,安装了N多额外的包,最后的确把HEARTBEAT安装起来了,我光是找各种安装包就花了一天时间,
后来发现同时安装只需要安装很少几个依赖包就可以了。
注意 严重大坑 红色部分
Share1 IPaddr::10.10.10.40/24/eth1 drbddisk::r0 Filesystem::/dev/drbd0::/drbd_data::ext4 killnfsd
此处又是一个大坑,如果不明白Heartbeat目录结构的朋友估计要在这里被卡到死,因为默认yum安装Heartbeat,不会在/etc/ha.d/resource.d/创建drbddisk脚本,而且也无法在安装后从本地其他路径找到该文件。
本人卡在此处3天时间。一直不能切换。后来百度google一起上阵得到下列代码。(该段代码没有测试。用了一段简易的脚本代替)
# vi /etc/ha.d/resource.d/drbddisk
FIO 测试

|
|
随机读 |
顺序读 |
随机写 |
顺序写 |
混合随机读写 |
|
Drbd 主备模式(已挂载) |
iops=42637 |
iops=53681 |
iops=231 |
iops=12889 |
iops=331 |
|
Drbd 主备模式(未挂载) |
iops=1247 |
iops=18981 |
iops=108 |
iops=5277 |
iops=55 |
|
本地磁盘 |
iops=6945 |
iops=37850 |
iops=1018 |
iops=14943 |
iops=381 |
 有C++难题,加我!
有C++难题,加我!