

但是要求XML格式完整(浏览器能够正常打开),不过有时我们可能需要解析一些不规则的节点,这些节点不完全符合XML规则(例如没有唯一的根节点等,直接使用XmlDocument的Load方法会发生异常)。
使用XmlTextReader类似读文本的形式可以解析XML片段,如下:
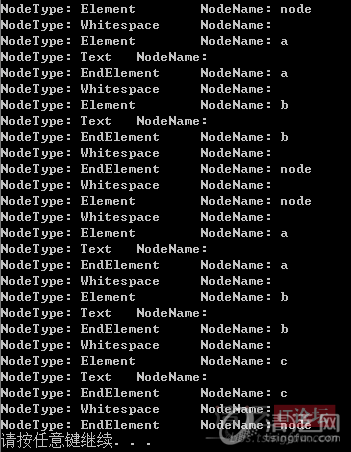
然后添加节点提取、过滤的逻辑就OK了。
C# 如何读取解析结构不完整的XML内容?

来源:清泛原创 2016-06-27 15:48:07 人气: 我有话说( 0 人参与)
一般情况下C#解析XML采用如下方式(本地XML、远程url都适用):public XmlDocument GetXMLFromUrl(string strUrl) { Xm...
上一篇:C# internal关键字的作用范围
下一篇:无法将方法组“Values”转换为非委托类型“System.Collections.Generic.List
技术
咨询
 有C++难题,加我!
有C++难题,加我!